- BBaum
-
Ein B-Baum ist in der Informatik eine Daten- oder Indexstruktur, die häufig in Datenbanken und Dateisystemen eingesetzt wird. Ein B-Baum ist ein immer vollständig balancierter Baum, der Daten sortiert nach Schlüsseln speichert. Das Einfügen, Suchen und Löschen von Daten in B-Bäumen ist in amortisiert logarithmischer Zeit möglich. B-Bäume wachsen – und schrumpfen – anders als die meisten Suchbäume von den Blättern hin zur Wurzel.
Inhaltsverzeichnis
Geschichte und Namensgebung
Der B-Baum wurde 1972 von Rudolf Bayer und Edward M. McCreight entwickelt. Er erwies sich als ideale Datenstruktur zur Verwaltung von Indizes für das relationale Datenmodell, das im gleichen Jahr von Edgar F. Codd entwickelt wurde. Diese Kombination führte zur Entwicklung des ersten SQL-Datenbanksystems System R bei IBM.
Die Erfinder lieferten keine Erklärung über die Herkunft des Namens B-Baum. Die häufigste Interpretation ist, dass B für balanciert steht. Weitere Interpretationen sind B für Bayer, Broad, Bushy, oder Boeing, da Rudolf Bayer für Boeing Scientific Research Labs gearbeitet hat.
B-Baum steht nicht für Binärbaum.
Idee und Übersicht
In einem B-Baum kann ein Knoten - im Unterschied zu Binärbäumen - mehr als 2 Kind-Knoten haben. Dies ermöglicht es, mit einer variablen Anzahl Schlüssel (oder Datenwerte) pro Knoten die Anzahl der bei einer Datensuche zu lesenden Knoten zu reduzieren. Die maximale erlaubte Anzahl der Schlüssel ist von einem Parameter t, dem Verzweigungsgrad (oder Ordnung) des B-Baumes, abhängig. Die Bedeutung von t (die Ordnung des B-Baumes) ist je nach Definition unterschiedlich: Entweder bezeichnet t die maximale Anzahl von Kindknoten - in diesem Fall ist die maximal erlaubte Anzahl von Schlüsseln (t − 1), oder die minimal erlaubte Anzahl von Kindknoten - in diesem Fall wäre die maximal erlaubte Anzahl an Schlüsseln 2t − 1.
Anwendung finden B-Bäume unter anderem bei Datenbanksystemen, die mit sehr großen Datenmengen umgehen müssen, von denen nur ein Bruchteil gleichzeitig in den Hauptspeicher eines Rechners passt. Die Daten sind daher persistent auf Hintergrundspeicher (z. B. Festplatten) abgelegt und können blockweise gelesen werden. Ein Knoten des Binärbaumes kann dann als ein Block gelesen bzw. gespeichert werden. Durch den großen Verzweigungsgrad bei B-Bäumen wird die Baumhöhe und damit die Anzahl der (langsamen) Schreib-/Lesezugriffe reduziert. Die variable Schlüsselmenge pro Knoten vermeidet zusätzlich häufiges Balancieren des Baumes.
Ein vollständig besetzter B-Baum, in dem t als die maximal erlaubte Anzahl von Kindknoten und h als die Höhe des Baums definiert ist, speichert gerade th − 1 Schlüssel. So können etwa bei einem entsprechend groß gewählten t (z. B. t = 1024) bei einer Höhe von h = 4 bereits 10244 − 1 = (210)4 − 1 = 240 − 1 Schlüssel gespeichert werden. Da eine Suchoperation höchstens h + 1 Knotenzugriffe benötigt, müssen für jede Suchanfrage in einem solchen Baum höchstens fünf Baumknoten inspiziert werden.
Definitionen
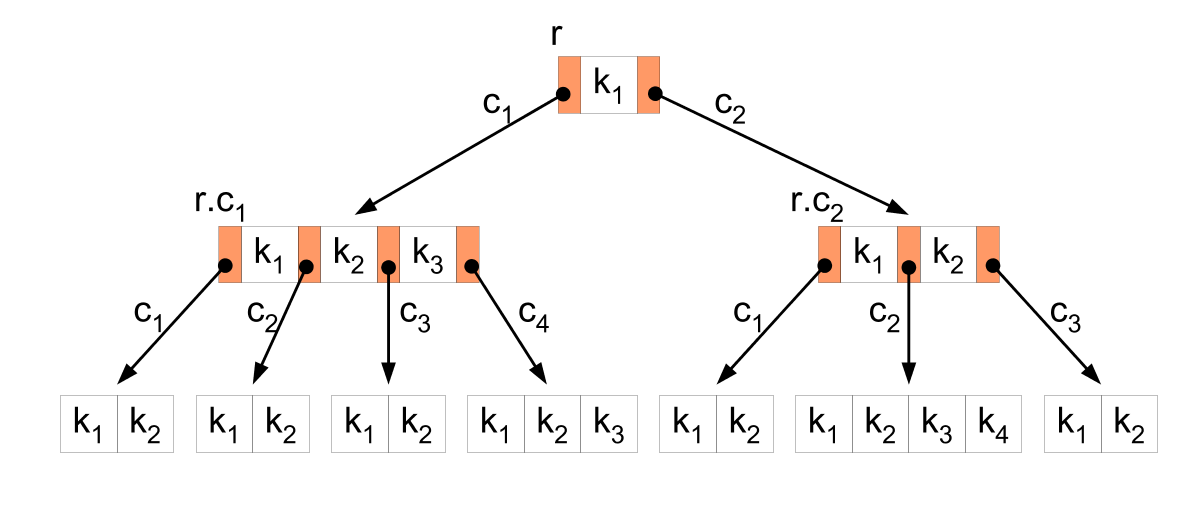
 Abbildung 1: B-Baum
Abbildung 1: B-Baum- Ein Knoten eines B-Baumes speichert
- eine variable Anzahl s von Schlüsseln
 (und optional ein pro Schlüssel zugeordnetes Datenelement),
(und optional ein pro Schlüssel zugeordnetes Datenelement), - eine Markierung isLeaf, die angibt, ob es sich bei dem Knoten um ein Blatt oder einen inneren Knoten handelt.
- Falls es sich um einen inneren Knoten handelt, zusätzlich s + 1 Verweise auf Kindknoten.
- eine variable Anzahl s von Schlüsseln
- Für die Schlüssel in einem B-Baum gilt eine gegenüber binären Suchbäumen verallgemeinerte Sortierungsbedingung:
- Alle Schlüssel eines Knotens sind aufsteigend sortiert.
- Bei einem inneren Knoten x teilen seine Schlüssel x.ki die Schlüsselbereiche seiner Unterbäume x.cj in s + 1 Teilbereiche ein. In einem Unterbaum x.cj kommen folglich nur Schlüssel k vor, für die gilt:
- k < x.kj, falls j = 1
- x.kj − 1 < k < x.kj, falls
- x.kj − 1 < k, falls j = s + 1
- Alle Blattknoten des B-Baumes befinden sich in gleicher Tiefe. Die Tiefe der Blattknoten ist gleich der Höhe h des Baumes.
- Es gilt folgende Beschränkung für die erlaubte Anzahl von Kindverweisen bzw. Schlüsseln pro Knoten. Dazu wird eine Konstante t festgelegt, die den minimalen Verzweigungsgrad von Baumknoten angibt.
- Alle Knoten außer der Wurzel haben
- mindestens t − 1 und höchstens 2t − 1 Schlüssel und
- mindestens t und höchstens 2t Kindverweise, wenn es sich um innere Knoten handelt.
- Die Wurzel hat
- mindestens 1 und höchstens 2t − 1 Schlüssel, wenn der B-Baum nicht leer ist, und
- mindestens 2 und höchstens 2t Kindverweise, wenn die Höhe des Baumes größer 0 ist.
- Alle Knoten außer der Wurzel haben
Eigenschaften
Für die Höhe h eines B-Baumes mit n gespeicherten Datenelementen gilt:
Damit sind im schlimmsten Fall immer noch Zugriffe auf O(log(n)) Baumknoten zum Auffinden eines Datenelements notwendig. Die Konstante dieser Abschätzung ist aber deutlich geringer als bei (balancierten) binären Suchbäumen mit Höhe log2(n):
Bei einem minimalen Verzweigungsgrad von t = 1024 benötigt ein B-Baum damit Zugriffe auf zehn mal weniger Knoten zum Auffinden eines Datenelements. Wenn der Zugriff auf einen Knoten die Dauer der gesamten Operation dominiert (wie das beim Zugriff auf Hintergrundspeicher der Fall ist), ergibt sich dadurch eine zehnfach erhöhte Ausführungsgeschwindigkeit.
Spezialfälle und Varianten
Für den Spezialfall t = 2 spricht man von 2-3-4-Bäumen, da Knoten in einem solchen Baum 2, 3 oder 4 Kinder haben können. Varianten des B-Baumes sind B+-Bäume und B*-Bäume.
Operationen
Suchen
Die Suche nach einem Schlüssel k liefert denjenigen Knoten x, der diesen Schlüssel speichert, und die Position i innerhalb dieses Knotens, für die gilt, dass k = x.ki. Enthält der Baum den Schlüssel k nicht, liefert die Suche das Ergebnis nicht enthalten.
Die Suche läuft in folgenden Schritten ab:
- Die Suche beginnt mit dem Wurzelknoten r als aktuellem Knoten x .
- Ist x ein innerer Knoten,
- wird die Position j des kleinsten Schlüssels bestimmt, der größer oder gleich k ist.
- Existiert eine solche Position j,
- aber ist
 , kann der gesuchte Schlüssel nur in dem Unterbaum mit Wurzel x.cj enthalten sein. Die Suche wird daher mit Schritt 2 und dem Knoten x.cj als aktuellem Knoten fortgesetzt.
, kann der gesuchte Schlüssel nur in dem Unterbaum mit Wurzel x.cj enthalten sein. Die Suche wird daher mit Schritt 2 und dem Knoten x.cj als aktuellem Knoten fortgesetzt. - ansonsten wurde der Schlüssel gefunden und (x,j) wird als Ergebnis zurückgeliefert.
- aber ist
- Existiert keine solche Position, ist der Schlüssel größer als alle im aktuellen Knoten gespeicherten Schlüssel. In diesem Fall kann der gesuchte Schlüssel nur noch in dem Unterbaum enthalten sein, auf den der letzte Kindverweis x.cx.s + 1 zeigt. In diesem Fall wird die Suche mit Schritt 2 und dem Knoten x.cx.s + 1 als aktuellem Knoten fortgesetzt.
- Ist x ein Blattknoten,
- Wird k in den Schlüsseln von x gesucht.
- Wenn der Schlüssel an Position j gefunden wird, ist das Ergebnis (x,j), ansonsten nicht enthalten.
 Abbildung 2: Suche im B-Baum
Abbildung 2: Suche im B-BaumIn nebenstehender Abbildung ist die Situation während der Suche nach dem Schlüssel k = 9 dargestellt. Im Schritt 2 aus obigem Algorithmus wird im aktuellen Knoten x die kleinste Position j gesucht, für die
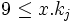 gilt. Im konkreten Beispiel wird die Position 2 gefunden, da
gilt. Im konkreten Beispiel wird die Position 2 gefunden, da 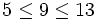 gilt. Die Suche wird daher im rot markierten Unterbaum x.c2 fortgesetzt, weil sich aufgrund der B-Baum-Eigenschaft (2) der gesuchte Schlüssel 9 nur in diesem Unterbaum befinden kann.
gilt. Die Suche wird daher im rot markierten Unterbaum x.c2 fortgesetzt, weil sich aufgrund der B-Baum-Eigenschaft (2) der gesuchte Schlüssel 9 nur in diesem Unterbaum befinden kann.Einfügen
 Abbildung 3: Teilen eines vollen B-Baum-Knotens.
Abbildung 3: Teilen eines vollen B-Baum-Knotens.Das Einfügen eines Schlüssels k in einen B-Baum geschieht immer in einem Blattknoten.
- In einem vorbereitenden Schritt wird der Blattknoten xinsert gesucht, in den eingefügt werden muss. Dabei werden Vorkehrungen getroffen, damit die Einfügeoperation nicht die B-Baum-Bedingungen verletzt und einen Knoten erzeugt, der mehr als 2t − 1 Schlüssel enthält.
- In einem abschließenden Schritt wird k unter Berücksichtigung der Sortierreihenfolge lokal in x eingefügt.
Die Suche von xinsert läuft mit zwei Unterschieden so ab, wie unter Suchen beschrieben. Diese Unterschiede sind:
- Das Einfügen eines neuen Schlüssels k geschieht immer in einem Blattknoten. Dem Einfügen muss daher immer ein kompletter Suchlauf vorhergehen, der ergibt, dass der Schlüssel k noch nicht existiert und in welchen Knoten er einzutragen ist. Dies kann nur ein Blattknoten sein, denn diese Aussage ist erst nach dem Durchsuchen über die gesamte Höhe des Baumes zulässig. Die Suche bricht jedoch in einem inneren Knoten ab, wenn dort der Schlüssel k bereits gefunden wird und ein Einfügen deshalb nicht notwendig ist.
- Bevor die Suche zu einem Kindknoten x.cj absteigt, wird überprüft, ob x.cj voll ist, d. h. bereits 2t − 1 Schlüssel enthält. In diesem Fall wird x.cj vorsorglich geteilt. Dies garantiert, dass die Einfügeoperation mit einem einzigen Baumabstieg durchgeführt werden kann und keine anschließenden Reparaturmaßnahmen zur Wiederherstellung der B-Baum-Bedingungen durchgeführt werden müssen.
Das Teilen eines vollen Baumknotens geschieht wie in Abbildung 3 gezeigt. Die Suche ist an Knoten x angekommen und würde zum Kindknoten x.c2 absteigen (roter Pfeil). Das heißt, die Suchposition ist j = 2. Da dieser Kindknoten voll ist, muss er vor dem Abstieg geteilt werden, um zu garantieren, dass eine Einfügung möglich ist. Ein voller Knoten hat mit 2t − 1 immer eine ungerade Anzahl von Schlüsseln. Der mittlere davon (in der Abbildung ist das Schlüssel x.c2.k3) wird im aktuellen Knoten an der Suchposition j eingefügt. Der Knoten x.c2 wird in zwei gleich große Knoten mit jeweils t − 1 Schlüsseln geteilt und diese über die beiden neuen Zeigerpositionen verlinkt (zwei rote Pfeile im Ergebnis). Die Suche steigt anschließend entweder in den Unterbaum x.c2 oder x.c3 ab, je nachdem, ob der einzufügende Schlüssel kleinergleich dem mittleren Schlüssel des geteilten Knotens ist oder nicht.
Löschen
Das Löschen eines Schlüssels kdelete ist eine komplexere Operation als das Einfügen, da hier auch der Fall betrachtet werden muss, dass ein Schlüssel aus einem inneren Knoten gelöscht wird. Der Ablauf ist dabei wie die Suche nach einem geeigneten Platz zum Einfügen eines Schlüssels allerdings mit dem Unterschied, dass vor dem Abstieg in einen Unterbaum überprüft wird, ob dieser genügend Schlüssel (
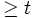 ) enthält, um eine eventuelle Löschoperation ohne Verletzung der B-Baum-Bedingungen durchführen zu können. Dieses Vorgehen ist analog zum Einfügen und vermeidet anschließende Reparaturmaßnahmen.
) enthält, um eine eventuelle Löschoperation ohne Verletzung der B-Baum-Bedingungen durchführen zu können. Dieses Vorgehen ist analog zum Einfügen und vermeidet anschließende Reparaturmaßnahmen.Enthält der Unterbaum, den die Suche für den Abstieg ausgewählt hat, die minimale Anzahl von Schlüsseln (t − 1), wird entweder eine Verschiebung oder eine Verschmelzung durchgeführt. Wird der gesuchte Schlüssel in einem Blattknoten gefunden, kann er dort direkt gelöscht werden. Wird er dagegen in einem inneren Knoten gefunden, passiert die Löschung wie in Löschen aus inneren Knoten beschrieben.
Verschiebung
 Abbildung 4: Verschieben eines Schlüssels im B-Baum.
Abbildung 4: Verschieben eines Schlüssels im B-Baum.Enthält der für den Abstieg ausgewählte Unterbaum nur die minimale Schlüsselanzahl t − 1, aber ein vorausgehender oder nachfolgender Geschwisterknoten hat mindestens t Schlüssel, wird ein Schlüssel in den ausgewählten Knoten verschoben, wie in nebenstehender Abbildung gezeigt. Die Suche hat hier x.c2 für den Abstieg ausgewählt (da x.k1 < kdelete < k2), dieser Knoten enthält aber nur t − 1 Schlüssel (roter Pfeil). Da der nachfolgende Geschwisterknoten x.c3 ausreichend viele Schlüssel enthält, kann von dort der kleinste Schlüssel x.c3.k1 in den Vaterknoten verschoben werden, um im Gegenzug den Schlüssel x.k2 als zusätzlichen Schlüssel in den für den Abstieg ausgewählten Knoten zu verschieben. Dazu wird der linke Unterbaum von x.c3.k1 zum neuen rechten Unterbaum des verschobenen Schlüssels x.k2. Man kann sich leicht davon überzeugen, dass diese Rotation die Sortierungsbedingungen erhält, da für alle Schlüssel k im verschobenen Unterbaum vor und nach der Verschiebung die Forderung
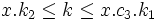 gilt. Eine symmetrische Operation kann zur Verschiebung eines Schlüssels aus einem vorausgehenden Geschwisterknoten durchgeführt werden.
gilt. Eine symmetrische Operation kann zur Verschiebung eines Schlüssels aus einem vorausgehenden Geschwisterknoten durchgeführt werden.Verschmelzung
 Abbildung 5: Verschmelzen zweier B-Baum Kindknoten.
Abbildung 5: Verschmelzen zweier B-Baum Kindknoten.Enthalten sowohl der für den Abstieg ausgewählte Unterbaum x.c2 als auch sein unmittelbar vorausgehender und nachfolgender Geschwisterknoten genau die minimale Schlüsselanzahl, ist eine Verschiebung nicht möglich. In diesem Fall wird eine Verschmelzung des ausgewählten Unterbaumes mit dem vorausgehenden oder nachfolgenden Geschwisterknoten gemäß nebenstehender Abbildung durchgeführt. Dazu wird der Schlüssel aus dem Vaterknoten x, welcher die Wertebereiche der Schlüssel in den beiden zu verschmelzenden Knoten trennt, als mittlerer Schlüssel in den verschmolzenen Knoten verschoben. Die beiden Verweise auf die jetzt verschmolzenen Kindknoten werden durch einen Verweis auf den neuen Knoten ersetzt.
Da der Algorithmus vor dem Abstieg in einen Knoten sicherstellt, dass dieser mindestens t anstelle der von den B-Baum-Bedingungen geforderten t − 1 Schlüssel enthält, ist gewährleistet, dass der Vaterknoten x eine ausreichende Schlüsselanzahl enthält, um einen Schlüssel für die Verschmelzung zur Verfügung zu stellen. Nur im Fall, dass zwei Kinder des Wurzelknotens verschmolzen werden, kann diese Bedingung verletzt sein, da die Suche bei diesem Knoten beginnt. Die B-Baum-Bedingungen fordern für den Wurzelknoten mindestens einen Schlüssel, wenn der Baum nicht leer ist. Bei Verschmelzung der letzten zwei Kinder des Wurzelknotens, wird aber sein letzter Schlüssel in das neu entstehende einzige Kind verschoben, was zu einem leeren Wurzelknoten in einem nicht leeren Baum führt. In diesem Fall wird der leere Wurzelknoten gelöscht und durch sein einziges Kind ersetzt.
Löschen aus inneren Knoten
 Abbildung 6: Löschen eines Schlüssels aus einem inneren Knoten.
Abbildung 6: Löschen eines Schlüssels aus einem inneren Knoten.Wird der zu löschende Schlüssel kdelete bereits in einem inneren Knoten gefunden (kdelete = x.k2 in nebenstehender Abbildung), kann dieser nicht direkt gelöscht werden, weil er für die Trennung der Wertebereiche seiner beiden Unterbäume x.c2 und x.c3 benötigt wird. In diesem Fall wird sein symmetrischer Vorgänger (oder sein symmetrischer Nachfolger) gelöscht und an seine Stelle kopiert. Der symmetrische Vorgänger ist der größte Blattknoten im linken Unterbaum x.c2, befindet sich also dort ganz rechts außen. Der symmetrische Nachfolger ist entsprechend der kleinste Blattknoten im rechten Unterbaum x.c3 und befindet sich dort ganz links außen. Die Entscheidung, in welchen Unterbaum der Abstieg für die Löschung stattfindet, wird davon abhängig gemacht, welcher genügend Schlüssel enthält. Haben beide nur die minimale Schlüsselanzahl, werden die Unterbäume verschmolzen und anschließend die Löschung im neu entstandenen Kindknoten durchgeführt.
Beispiel
 Abbildung 7: Evolution eines B-Baumes
Abbildung 7: Evolution eines B-BaumesNebenstehende Abbildung zeigt die Entwicklung eines B-Baumes mit minimalem Verzweigungsgrad t = 2. Knoten in einem solchen Baum können minimal einen und maximal drei Schlüssel speichern und haben zwischen zwei und vier Verweise auf Kindknoten. Man spricht daher auch von einem 2-3-4-Baum. In einer praktischen Anwendung würde man dagegen einen B-Baum mit wesentlich größerem Verzweigungsgrad verwenden.
Folgende Operationen wurden auf einem 2-3 Baum (siehe Abbildung rechts) durchgeführt:
- a–c) Einfügen von 5, 13 und 27 in einen anfangs leeren Baum.
- d–e) Einfügen von 9 führt zum Teilen des Wurzelknotens.
- f) Einfügen von 7 in einen Blattknoten.
- g–h) Einfügen von 3 führt zum Teilen eines Knotens.
- i–j) Um 9 löschen zu können, wird ein Schlüssel aus einem Geschwisterknoten verschoben.
- k–l) Das Löschen von 7 führt zum Verschmelzen von zwei Knoten.
- m) Löschen von 5 aus einem Blatt.
- n–q) Löschen von 3 führt zur Verschmelzung der letzten zwei Kinder des Wurzelknotens. Der entstehende leere Wurzelknoten wird durch sein einziges Kind ersetzt.
Siehe auch
- R-Baum ist ein verwandtes Indexverfahren für mehrdimensionale Daten.
- B+-Baum und B*-Baum sind B-Baum-Varianten.
- 2-3-4-Baum ist ein Spezialfall eines B-Baumes mit minimalem Verzweigungsgrad t = 2.
- AVL-Baum
- Rot-Schwarz-Baum
Literatur
deutsch
- Niklaus Wirth: Algorithmen und Datenstrukturen mit Modula-2, Stuttgart 1986, ISBN 3-519-02260-5
- T. Ottmann, P.Widmayer: Algorithmen und Datenstrukturen-3, Heidelberg; Berlin; Oxford: Spektrum, Akad. Verlag 1996, ISBN 3-827-40110-0, S. 317-327
englisch
- R. Bayer, E. McCreight: Organization and Maintenance of Large Ordered Indexes. In: Acta Informatica 1, 1972, S. 173–189
- R. Bayer, E. McCreight: Symmetric binary B-Trees: data structure and maintenance algorithms. In: Acta Informatica 1, 1972, S. 290–306
Weblinks
Tools zum Ausprobieren von B-Bäumen:
- http://slady.net/java/bt – B-Baum Java Applet
- http://www.fh-augsburg.de/~mweiss/applets/bTree.shower2.html – Java Applet
- http://www.engin.umd.umich.edu/CIS/course.des/cis350/treetool/ (produziert teilweise abweichende Ergebnisse zu der anderen Alternative)
Erklärung mit Beispielen:
- http://www.lexolino.de/c,technik_informatik_algorithmentheorie,bayer-b%E4ume - Einfache B-Baum Implementierung
- http://wwwbayer.in.tum.de/lehre/WS2001/HSEM-bayer/BTreesAusarbeitung.pdf - Ausarbeitung über B-Bäume
- Ein Knoten eines B-Baumes speichert
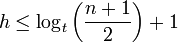
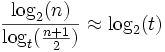






Wikimedia Foundation.