- Bayes-Filter
-
Der bayessche Filter (auch als bayesischer Filter bezeichnet) ist ein statistischer Filter, der auf dem bayesschen Wahrscheinlichkeitsbegriff aufbaut. Sein Name leitet sich vom englischen Mathematiker Thomas Bayes (etwa 1702−1761) ab.
Markow-Filter stellen eine Weiterentwicklung dar, bei der nicht nur einzelne Wörter, sondern ganze Wortketten und Kombinationsmöglichkeiten bewertet werden.
Inhaltsverzeichnis
Anwendung in E-Mails
E-Mails werden mit Hilfe des bayesschen Filters folgendermaßen untersucht: Von charakteristischen Wörtern in einer E-Mail (Ereignis) wird auf die Eigenschaft geschlossen, als SPAM eingeordnet zu werden. Dieses statistische Filtern, zuerst 1998 von Sahami et al.[1] vorgeschlagen und ab 2002 durch einen einflussreichen Artikel von Paul Graham[2] popularisiert, soll vorhersagen, ob eine E-Mail Spam ist oder nicht. Der Filter wird von vielen Antispam-Programmen benutzt und ist beispielsweise in den E-Mail-Clients von Opera und Mozilla Thunderbird implementiert.
Statistische Gegenmaßnahmen basieren auf Wahrscheinlichkeits-Methoden, abgeleitet vom Bayes-Theorem. Bayessche Filter sind oft „lernend“ (auch „selbstlernend“) organisiert und setzen auf Worthäufigkeiten in bereits vom Benutzer erhaltenen und klassifizierten E-Mails. Ein bayesscher Filter wird durch seinen Benutzer trainiert, indem dieser seine E-Mails in erwünschte (Ham) und unerwünschte (Spam) einteilt. Der bayessche Filter stellt nun eine Liste mit Wörtern zusammen, die in unerwünschten E-Mails vorkommen. Hat der Benutzer z.B. E-Mails mit den Begriffen „Sex“ und „Viagra“ als Spam gekennzeichnet, haben alle E-Mails mit diesen Begriffen eine hohe Spamwahrscheinlichkeit. Begriffe aus erwünschten E-Mails wie „Verabredung“ oder „Bericht“ führen dann zu geringer Spamwahrscheinlichkeit. Allerdings reichen einzelne Schlüsselwörter nicht aus, relevant ist die Gesamtsumme der Bewertungen der einzelnen Wörter.
Der Filter schafft bereits nach kurzem Training mit zirka 30 E-Mails erstaunlich hohe Trefferquoten − auch wenn für die produktive Nutzung ein Training mit mindestens mehreren hundert Mails beider Kategorien empfohlen wird. Er wird von vielen Providern zum Abfangen von Spam verwendet.
Das entscheidende Risiko besteht für den Benutzer, dass ihm eine reguläre Mail entgeht, also die falsch-positiven Fälle. Für einen Privatmann, der zusätzlich mit Whitelists arbeitet, kann dies noch hinnehmbar sein, jedoch riskieren Firmen demgegenüber, dass wichtige Anfragen von Neukunden verlorengehen. Diese Gefahr ist jedoch bei richtigem Training des Filters wesentlich geringer als die Gefahr, dass eine Mail bei manueller Filterung oder aus anderen Gründen übersehen, gelöscht oder einfach nur vergessen wird. Wichtig ist nur, dass man vor allem in der Anfangsphase des Trainings nicht nur die unerwünschten Mails markiert, sondern auch die regulären.
Die Versender von Spam sehen aber auch nicht tatenlos zu. Werbebotschaften werden z.B. in Bildern untergebracht, damit sie der Filter nicht findet, und verdächtige Begriffe werden bewusst falsch (z.B. „V|agra“ oder „Va1ium“) oder mit eingestreuten Leerzeichen geschrieben. Allerdings bewertet der Filter auch HTML-Tags wie „img“ und „src“ negativ, so dass Bilder in E-Mails ein recht guter Hinweis auf Spam sind, ebenso wie die falsch geschriebenen Wörter, die vom Filter ja ebenfalls gelernt und natürlich mit einer extrem hohen Spamwahrscheinlichkeit bewertet werden.
In jüngerer Zeit ist häufig eine Methode zu beobachten, bei der zufällige Zitate oder ganze Kapitel aus der Weltliteratur (evtl. in weißer Schrift oder als Meta-Tag unlesbar) eingefügt werden, um die statistischen Maßnahmen auszutricksen. Dies ist aber ebenfalls keine sehr erfolgreiche Strategie, weil zufällig ausgewählte ‚harmlose‘ Begriffe oder Sätze weder eine besonders hohe noch eine besonders niedrige Spamwahrscheinlichkeit haben, so dass sie in der Gesamtbewertung aller in der Mail vorkommenden Begriffe keine Rolle spielen.
Eine Besonderheit in nicht englischsprachigen Ländern entsteht daraus, dass Spam überwiegend in englischer Sprache verfasst ist. Die Trefferwahrscheinlichkeit eines bayesschen Filters dürfte daher in diesen Ländern höher liegen, aber auch die Gefahr, dass eine erwünschte englischsprachige Mail fälschlicherweise als Spam erkannt wird.
Das Filtern auf statistischen Grundlagen ist eine Art Text-Klassifikation. Eine Anzahl von Forschern der angewandten Linguistik, die sich mit maschinellem Lernen befassen, haben sich bereits diesem Problem gewidmet.
Mathematische Grundlage
Der Satz von Bayes lautet
Dieser kann benutzt werden, um die Wahrscheinlichkeit zu berechnen, dass eine E-Mail Spam ist, wenn ein bestimmtes Wort enthalten ist:
Hierbei ist
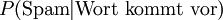 die Wahrscheinlichkeit, dass eine E-Mail Spam ist, wenn ein bestimmtes Wort im Text vorkommt.
die Wahrscheinlichkeit, dass eine E-Mail Spam ist, wenn ein bestimmtes Wort im Text vorkommt.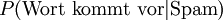 die Wahrscheinlichkeit, dass ein bestimmtes Wort in einer Spam-E-Mail vorkommt.
die Wahrscheinlichkeit, dass ein bestimmtes Wort in einer Spam-E-Mail vorkommt.
Siehe auch
- Weitverbreiteter und ausgezeichneter[3][4][5][6] Freie-Software-Spamfilter, der den Bayesschen Filter implementiert und der sowohl auf Benutzer- als auch auf Mailserver-Ebene eingesetzt werden kann
Weblinks
- spambayes kostenloser Bayesscher Spamfilter, erhältlich als Outlook-Plugin oder als Proxy-Lösung für alle anderen Mail-Clients
- b8 (früher bayes-php) ein in PHP implementierter Bayes-Filter für Weblogs oder Gästebücher (bilingual: Deutsch und Englisch)
- Spamihilator sehr guter Filter, Freeware, deutsch
- Thunderbird-Erweiterung MailClassifier, ein auf dem Bayesschen Filter beruhender E-Mail-Filter zur automatisierten Klassifizierung und Kategorisierung von E-Mails
- Die Mathematik im Bayes Spamfilter, die benötigten Hilfsmittel und ein Rechenbeispiel
Einzelnachweise
- ↑ M. Sahami, S. Dumais, D. Heckerman, E. Horvitz: A Bayesian approach to filtering junk e-mail, AAAI'98 Workshop on Learning for Text Categorization, 1998.
- ↑ P. Graham: A Plan for Spam, August 2002.
- ↑ The 2003 OSDir.com Editor's Choice Awards in Open Source (osdir.com)
- ↑ SpamAssassin Takes Top Anti-Spam Honors (earthweb.com)
- ↑ Datamation.com Announces Product of the Year Winners 2006 (earthweb.com)
- ↑ Linux New Media Awards 2006 (linuxnewmedia.com)
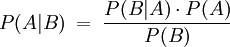
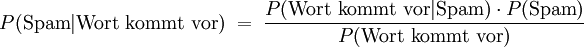
Wikimedia Foundation.