- Shift-And-Algorithmus
-
Der Baeza-Yates-Gonnet-Algorithmus bzw. Shift-or-Algorithmus, der auch unter dem Namen Shift-and bekannt ist, löst das String Matching-Problem indem er einen nichtdeterministischen Automaten simuliert. Unter anderem wird eine Abwandlung dieses Algorithmus bei dem Unix-Tool grep benutzt.
Da die Implementierung auf Bit-Operationen zurückgeführt werden kann, ist der Algorithmus alleine von der Ausführung her bereits sehr effizient. Kombiniert man dies mit dem zu Grunde liegenden System (im Preprocessing einmal Schleife über das Muster, während der Suche einmal Schleife über den Text) ergibt sich ein extrem effizienter Algorithmus.
Inhaltsverzeichnis
Grundlage
Grundlage des Algorithmus bildet eine Menge von Vektoren Rj mit folgender Definition:
![R_{j+1}[i] = \begin{cases} 1, & \mbox{falls }i=0\\1, & \mbox{falls }R_j[i-1]=1 \mbox{ und } Musterzeichen_i=Eingabezeichen_{j+1}\\0, & \mbox{sonst}\end{cases}](/pictures/dewiki/49/1993873c87e253627ade707253d31bd8.png)
Anschaulich bedeutet dies, dass Rj[i] genau dann 1 ist, wenn nach der Verarbeitung von j Zeichen des Textes die letzten i Zeichen mit den ersten i Zeichen des Suchmusters übereinstimmen.
Ein Treffer für ein Suchmuster mit Länge m ist demnach gefunden, falls Rj[m] = 1.
Weiterhin werden die charakteristischen Vektoren für alle möglicherweise im Text vorkommenden Zeichen benötigt:
![s_a[i] = \begin{cases} 1, & \mbox{falls im Suchmuster an Stelle } i \mbox{ das Zeichen } a \mbox{ steht}\\0, & \mbox{sonst} \end{cases}](/pictures/dewiki/53/5178484b48867b5d20d5891f7bd4ed95.png)
Beispiel:
Suchmuster abcac, Länge m = 5
Charakteristische Vektoren:

Ablauf (exaktes Matching)
Um den Ablauf zu vereinfachen, wird zunächst eine spezielle Bit-Operation Bitshift bzw.
 für den Vektor R eingeführt:
für den Vektor R eingeführt: 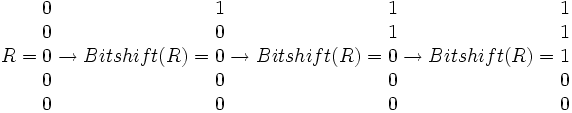
Der Algorithmus für exakte Übereinstimmungen lässt sich nun auf wenige einfache Schritte reduzieren:
- Initialisiere den R-Vektor mit 0 (für alle Positionen) und beginne mit dem ersten Zeichen des zu durchsuchenden Textes
- Verschiebe alle Bits in R mittels Bitshift um eine Position nach rechts.
- Führe eine UND-Verknüpfung von R und dem charakteristischen Vektor des aktuellen Textzeichens durch.
- Gehe zum nächsten Textzeichen. Falls Ende erreicht, breche ab, sonst gehe zu (2)
Die Schritte (2) und (3) führen bei genauer Betrachtung genau die Berechnungsvorschrift für R aus: Durch das Shiften wird aus dem "alten" R das Zeichen an Stelle i an die Stelle i + 1 angelegt (entspricht in Kombination mit UND der Bedingung Rj[i] = 1). Der charakteristische Vektor des aktuellen Textzeichens enthält an der Stelle i + 1 genau dann eine 1, falls Muster und Text hier übereinstimmen. Durch das UND werden beide Bedingungen verknüpft.
Beispiel (exaktes Matching)
Muster: abcac, m = 5
Text: abcabcac

Da R8[5] = 1 liegt ein Treffer bei 8 − 5 + 1 (Position − Musterlänge + Korrektur für erstes Zeichen) vor.
Erweiterung (approximatives Matching)
Der Algorithmus kann durch leichte Modifikationen eine fehlertolerante Suche durchführen. Hierfür wird der Vektor R aufgeteilt:
![R_j^0[i]](/pictures/dewiki/51/3f8385abe35c0aeaf3fda9ed7d154fc5.png) : entspricht dem vorherigen Rj[i]; Der Index 0 steht für die Anzahl der aufgetretenen Fehler.
: entspricht dem vorherigen Rj[i]; Der Index 0 steht für die Anzahl der aufgetretenen Fehler.![R_j^1[i]](/pictures/dewiki/54/6b88d371178eef4e5b3283461adc9b6d.png) : Bezeichnet einen R-Vektor, der auf Treffer mit maximal einem Fehler ausgerichtet ist.
: Bezeichnet einen R-Vektor, der auf Treffer mit maximal einem Fehler ausgerichtet ist.- ...
![R_j^k[i]](/pictures/dewiki/50/201c38820b57768e59a56ae696e513f7.png) : Bezeichnet einen R-Vektor, der auf Treffer mit maximal k Fehlern ausgerichtet ist.
: Bezeichnet einen R-Vektor, der auf Treffer mit maximal k Fehlern ausgerichtet ist.
Achtung: Bei den fehlerbehafteten Vektoren ist die obige Interpretation mit „nach j Zeichen stimmen die letzten i mit den ersten i des Musters überein“ schwierig und nicht mehr unbedingt einleuchtend.
Die Berechnungsvorschrift für
bleibt unverändert. Für Fehlervektoren 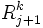 wird nach der verursachenden Aktion unterschieden:
wird nach der verursachenden Aktion unterschieden:Einfügen eines Zeichens in das Suchmuster
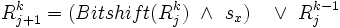
Erläuterung: Der erste Teil des Ausdrucks beschreibt den Fall, dass bereits k Fehler vorhanden sind, aber das aktuelle Zeichen von Text und Muster übereinstimmen. Der zweite Teil beschreibt den Fehlerfall: Bisher (in j) lagen nur k - 1 Fehler vor, das aktuelle Zeichen kann also in das Muster eingefügt werden.
Interpretation:
![R_j^k[i]=1](/pictures/dewiki/53/5217ea77fce99b502448fd9e14c8b0fc.png) , falls nach j Zeichen der Eingabe von den letzten i + k Zeichen mindestens i Zeichen mit dem Suchmuster übereinstimmen und der Rest durch Einfügen der fehlenden Zeichen zur Übereinstimmung gebracht werden kann.
, falls nach j Zeichen der Eingabe von den letzten i + k Zeichen mindestens i Zeichen mit dem Suchmuster übereinstimmen und der Rest durch Einfügen der fehlenden Zeichen zur Übereinstimmung gebracht werden kann.Löschen eines Zeichens aus dem Suchmuster
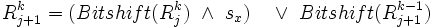
Erläuterung: Der erste Teil des Ausdrucks beschreibt den Fall, dass bereits k Fehler vorhanden sind, aber das aktuelle Zeichen von Text und Muster übereinstimmen. Der zweite Teil beschreibt den Fehlerfall: Schaut man sich bei j + 1 Zeichen des Textes nicht die ersten i Zeichen an, sondern nur die ersten i − 1 (im Vektor die Position darüber), so stimmt das Muster bis auf k - 1 Fehler überein. Das i. Zeichen des Musters wird daraufhin einfach gelöscht.
Ersetzen eines Zeichens im Muster
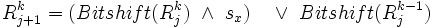
Erläuterung: Der erste Teil des Ausdrucks beschreibt den Fall, dass bereits k Fehler vorhanden sind, aber das aktuelle Zeichen von Text und Muster übereinstimmen. Der zweite Teil beschreibt den Fehlerfall: Nach j Zeichen stimmten die letzten i − 1 Zeichen überein. Ersetzt man nun also das i. Zeichen im Muster durch das j + 1. Zeichen des Textes, stimmen auch nach j + 1 Zeichen die letzten i Zeichen mit den ersten i Zeichen des „neuen“ Musters überein.
Die Varianten können mittels ODER beliebig verknüpft werden.
Weblinks
- StringSearch – high-performance pattern matching algorithms in Java (Implementierungen des Shift-Or-Algorithmus in Java; englisch)
Wikimedia Foundation.