- Sprungvorhersage
-
Die Sprungvorhersage (englisch branch prediction) wird in der (Mikro-)Rechnerarchitekur verwendet und behandelt das Problem von Mikroprozessoren, alle Stufen ihrer Pipeline möglichst immer und sinnvoll auszulasten.
Inhaltsverzeichnis
Übersicht
Unter Sprungvorhersage (auch Verzweigungsvorhersage) versteht man:
- Die Vorhersage, ob ein bedingter Sprung ausgeführt wird
- Die Zieladresse eines Sprunges zu ermitteln
Es existieren zwei Arten von Sprüngen:
- bedingter Sprung (z. B. von einer IF-Abfrage)
- unbedingter Sprung (z. B. GOTO, RETURN, Method-Calls)
In modernen Prozessoren werden Maschinenbefehle in mehreren Verarbeitungsschritten innerhalb einer Verarbeitungskette (Pipeline (Prozessor)) ausgeführt. Um die Leistungsfähigkeit des Prozessors zu maximieren, wird, nachdem ein Befehl in die Pipeline geladen wurde und z. B. im nächsten Schritt mit der Analyse des Befehls fortgefahren werden soll, gleichzeitig mit dem Laden des nächsten Befehles begonnen. Es befinden sich also (meistens) eine ganze Reihe von Befehlen zur sequentiellen Abarbeitung in der Pipeline. Wird jetzt am Ende der Pipeline festgestellt, dass ein bedingter Sprung ausgeführt wird, so sind alle in der Pipeline anstehenden und teilabgearbeiteten Befehle ungültig. Der Prozessor löscht jetzt die Pipeline und lädt diese dann neu von der neuen Programmcodeaddresse. Je mehr Stufen die Pipeline hat, desto mehr Zeit geht dadurch verloren, beispielsweise 30 Stufen führen bei 1 GHz zu einem Zeitverlust der einem Takt einer 33-MHz-CPU entspricht. Je öfter dies durchgeführt werden muss, um so langsamer wird das Programm ausgeführt.
Das Ziel: Möglichst frühes Erkennen eines Sprungbefehls und Erkennen seiner Sprungzieladresse, damit gleich die Daten der Zieladresse dem Sprungbefehl in die Pipeline folgen können.
Funktionsweise
Die Sprungvorhersage lässt sich in zwei Arten unterscheiden.
Statische Sprungvorhersage
Die statische Sprungvorhersage ändert ihre Vorhersage während des Programmablaufs nicht. Sie erreicht dadurch nur eine Vorhersagegenauigkeit von 55 bis 80 %. Diese Technik geht von bekannten Tatsachen aus, z. B. dass Schleifen häufig Sprünge ausführen, während dies bei Auswahlverfahren seltener vorkommt. Manche Compiler unterstützen den Mechanismus auch mit speziellen Flags im Befehlscode (Vorhersage wird beim Kompilieren eingebaut).
Dynamische Sprungvorhersage
Die dynamische Sprungvorhersage geschieht zur Laufzeit durch eine elektronische Verschaltung innerhalb der CPU. Sie benutzt verschiedene Techniken zur Erzeugung einer Vorhersage. Ihre Vorhersagegenauigkeit liegt bei bis zu 98 %. Die einfachste Methode spekuliert anhand der Sprungrichtung: Sprünge im Programmcode zurück sind in der Regel Schleifen, die oft mehrfach durchlaufen werden, sodass bei dieser prophylaktisch die Pipeline mit dem zurückliegenden Code gefüllt wird.
Erkannte bedingungslose Sprünge werden einfach vorab aus der Befehlswarteschlange aussortiert und diese dann mit dem Code vom Sprungziel weitergefüllt, bevor diese in die Pipeline eintreten.
Per-Address History
Wird ein Sprung erkannt, so wird dieser protokolliert und für weitere Sprungvorhersagen herangezogen (bei Schleifen werden Sprünge i. d. R. öfter vorkommen – so muss der Sprung nur einmal erkannt werden). Implementiert wird diese Technik z. B. von der Branch History Table (BHT).
Global History
Bei der globalen Vorgeschichte wird der komplette Pfad, den ein Programm genommen hat, protokolliert (über eine begrenzte Anzahl Schritte hinweg). Erkennt man nun, dass zwei Sprünge sich ähneln, könnten sie denselben Pfad nehmen – somit ist der Logik eventuell schon ein Teil dessen bekannt, was das Programm in Zukunft machen wird. Gespeichert wird der Pfad meist in einem Schieberegister. Für die Vorhersagen benutzt man entweder einen Zähler oder einen (trägen) Automaten. Implementiert wird diese Technik z. B. vom Branch Target Buffer (BTB).
Statische Sprungvorhersagetechniken
Stall/Freeze
Diese Technik hält einfach die ganze Pipeline kurz an. Wird in der ID-Stage ein Sprungbefehl festgestellt, wird die Pipeline solange angehalten (stalled/freezed), bis man in der EX-Stage weiß, ob der Sprung ausgeführt wird.
- Sprung wird nicht ausgeführt: mache normal weiter
- Sprung wird ausgeführt: Setze Programmzähler auf Sprungzieladresse und fülle die Pipeline mit den Instruktionen, die sich am Sprungziel befinden.
Predict taken
Geht einfach davon aus, dass jeder bedingte Sprung auch ausgeführt wird, d. h., wir stellen in der ID-Stage fest, dass ein Sprungbefehl vorliegt und beginnen schon mal die Zieladresse zu bestimmen und die dortigen Daten gleich in die Pipeline als Folgeinstruktionen zu laden. Wird in der EX-Stage allerdings festgestellt, dass der Sprung doch nicht stattfindet, war die vorherige Arbeit umsonst (verwendet bei Schleifen).
Predict not taken
Geht davon aus, dass jeder bedingte Sprung nicht ausgeführt wird und macht normal weiter. Dies bedeutet (sollte der Sprung wirklich nicht ausgeführt werden) einen guten Performancegewinn. Sollte in der EX-Stage festgestellt werden, dass der Sprung wider Erwarten doch ausgeführt wird, muss die Folgeinstruktion angehalten, der PC auf die Sprungzieladresse gestellt und damit dann die Pipeline gefüllt werden (verwendet bei Auswahlverfahren).
Delayed Branches
Wird in der ID-Stage ein Sprungbefehl festgestellt, ist noch unbekannt, ob er ausgeführt wird oder nicht. Daher bekommt jeder Sprungbefehl einen (oder mehrere) Delay-Slots, die mit unabhängigen, sinnvollen Instruktionen gefüllt werden können. Findet der Sprung nicht statt, wird nach dem Delay-Slot normal weitergemacht. Findet der Sprung statt, werden die Daten der Sprungzieladresse nach den Delay-Slot Instruktionen ausgeführt. Welche Daten in die Delay-Slots kommen können, ist Aufgabe des Compilers/Assemblerprogrammierers.
Dynamische Sprungvorhersagetechniken
Branch History Table (BHT)
Die BHT versucht, wie ihr Name schon sagt, ebenfalls die letzten Sprünge mitzuprotokollieren. Dazu verwendet sie einen Teil der Sprungbefehlsadresse als Hashwert. Im Allgemeinen nimmt man dafür den niederwertigen Adressanteil. Diese Adressteile können natürlich nicht immer eindeutig sein, so dass es Kollisionen geben kann (mehrere unterschiedliche Sprünge belegen denselben Platz in der Tabelle).
Die Tabelle wird nach jedem Sprung aktualisiert.
n-Bit träger Automat
Ist ein endlicher Automat, der Vorhersageinformationen liefert.
- 1-Bit-Automat
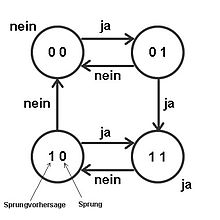
- Wird ein gespeicherter Sprung genommen, wird dessen Bit von 0 auf 1 gesetzt. Ein Problem ist aber, dass er alternierende Sprünge nicht berücksichtigt (bei Sprüngen, die z. B. nur bei jedem 2. Schleifendurchlauf stattfinden, würde das Bit immer wieder invertiert werden). Die Lösung hierfür ist ein n-Bit-Automat.

- n-Bit träger Automat
- Dieser setzt das Korrektheitsbit erst nach den n Fehlschlägen auf 0. Im Allgemeinen wird n = 2 verwendet. (Tests haben gezeigt, dass ab n > 2 die Leistungssteigerung nur noch minimal ist.) Beim ersten Schleifendurchlauf ist der Zustand 00, und die Bedingung sei wahr. Damit geht der Zustand nach 01 über. Ist beim nächsten Schleifendurchlauf die Bedingung wieder wahr, wird der Zustand 11 und sagt daher auch für alle weiteren Sprünge eine wahre Sprungbedingung vorher. Ist beim zweiten Durchlauf die Bedingung falsch, so geht der Zustand wieder nach 00 zurück. Ist der Zustand 11, so muss die Sprungbedingung zweimal falsch gewesen sein, bevor die Vorhersage wieder „falsch“ lautet. Mit anderen Worten: Nachdem zweimal in die gleiche Richtung gesprungen wurde, wird diese Richtung nun auch für die weiteren Sprünge vorhergesagt. Es lässt sich errechnen, dass bei diesem Verfahren die Wahrscheinlichkeit für die richtige Vorhersage bei 83 % liegt.
Bei gshare werden der Adressteil und die Sprungsignatur mit XOR verknüpft und in eine Tabelle abgelegt. Die Informationen der Tabelle werden dann zur Sprungvorhersage herangezogen. gshare kombiniert somit Per-Address History mit Global History. Da hier XOR als Hashverfahren genommen wird, können wieder Kollisionen entstehen.
Das Verfahren findet z. B. im AMD Athlon und Pentium III Anwendung.[1]
Übersicht
Verfahren Genauigkeit Hardwareaufwand Zeitverhalten statisch zur Laufzeit −− ++ ++ statisch zur Compilezeit − ++ ++ Per-Address History + + + Global History + + + gshare ++ + + Sprungzielvorhersage-Techniken
Besser als eine bloße Sprungvorhersage ist gleich eine Sprungzielvorhersage. Sobald man in der ID-Stage erkennt, dass es sich um einen Sprung handelt, kann man prüfen, ob dieser Sprung schon mal stattfand und ggf. sein Sprungziel aus einem Puffer holen. Somit kann man den Programmzähler sofort auf dieses Sprungziel stellen und die dortigen Instruktionen in die Pipeline laden.
Branch Target Buffer (BTB)
Der BTB (auch Sprungzielpuffer oder Branch Target Address Cache, BTAC) speichert genommene (tatsächlich ausgeführte) Sprünge in einer Tabelle ab.
Diese Tabelle enthält:
- Vorhersageinformationen
- Zieladressen
- Tags
Der BTB liefert immer eine Adresse zurück. Wird ein unbekannter Sprung abgefragt, so liefert er einfach die Folgeadresse. Wird aber ein bekannter Sprung abgefragt, so liefert er die Zieladresse.
Der BTB kann nicht immer korrekt arbeiten. Da z. B. RETURN-Anweisungen variable Zieladressen haben (Moving Targets), kann der BTB zu einem korrekten Sprung eine falsche Zieladresse abspeichern. Da in modernen Programmierhochsprachen objektorientiert programmiert wird, kommt es zu häufigen Methodenaufrufen und somit zu vielen Moving Targets. Um diese in der Hinsicht fatale Schwäche zu beheben, werden BTBs um einen Call-Return-Stapel erweitert.
Call-Return-Stapel
Dieser Stapel speichert alle Return-Adressen nach dem LIFO-Prinzip. Weiterhin wird von speziellen Call- und Return-Befehlen im Befehlssatz ausgegangen (wird also von einem normalen Sprung unterschieden).
Sonderbehandlung beider Sprünge im Branch Target Buffer (BTB).
- Call: Bei Aufruf wird in dem BTB zusätzlich die Adresse des Return-Befehls abgelegt.
- Return: Extra-Kennzeichnung des Befehls im BTB. Bei Aufruf eines so gekennzeichneten Befehls im BTB wird statt der Zieladresse aus dem BTB die oberste Adresse des Call-Return-Stacks genommen.
Somit kann gewährleistet werden, dass immer die richtige Rücksprungadresse benutzt wird.
Weblinks
- Ausarbeitung zu den grundlegendsten Themen der Rechnerarchitektur (Überblick) (Kapitel 7 - Branch Prediction)
- Simulator zur Sprungvorhersage in Prozessoren mit Befehlsphasenpipelining auf der Webseite von einem der Autoren
Einzelnachweise

Wikimedia Foundation.