- Clustering-Verfahren
-
Unter Clusteranalyse (der Begriff Ballungsanalyse wird selten verwendet) versteht man strukturentdeckende, multivariate Analyseverfahren zur Ermittlung von Gruppen (Clustern) von Objekten, deren Eigenschaften oder Eigenschaftsausprägungen bestimmte Ähnlichkeiten aufweisen.
Die an verschiedene Anforderungen angepassten Verfahren der Clusteranalyse lassen sich zur automatischen Klassifizierung, zur Erkennung von Mustern zum Beispiel in der Bildverarbeitung, zum Data-Mining oder im Information Retrieval einsetzen. Im Bereich Marketing wird dieses Analysewerkzeug gerne als Kundensegmentierungsverfahren verwendet, nicht zuletzt, weil es visuell präsentiert werden kann.
Inhaltsverzeichnis
Prinzip
Die zu untersuchenden Objekte werden als Zufallsvariablen aufgefasst und in der Regel in Form von Vektoren als Punkte in einem Vektorraum dargestellt, deren Dimensionen die Eigenschaftsausprägungen bilden. Ein Cluster ist eine Anhäufung von Punkten (Punktwolke), wobei bei Streudiagrammen zum Beispiel die Abstände zwischen den Punkten zueinander oder die Varianz innerhalb eines Clusters als Proximitätsmaße dienen.
Cluster können auch als Gruppe von Objekten definiert werden, die in Bezug auf einen berechneten Schwerpunkt eine minimale Abstandssumme haben. Dazu ist die Wahl eines Distanzmaßes erforderlich. In bestimmten Fällen sind die Abstände (bzw. umgekehrt die Ähnlichkeiten) der Objekte untereinander direkt bekannt und müssen nicht aus der Darstellung im Vektorraum ermittelt werden.
Geschichte
Historisch gesehen stammt das Verfahren aus der Taxonomie in der Biologie, wo über eine Clusterung von verwandten Arten eine Ordnung der Lebewesen ermittelt wird – allerdings wurden dort ursprünglich keine automatischen Berechnungsverfahren eingesetzt. Inzwischen können zur Bestimmung der Verwandtschaft von Organismen unter anderem ihre Gensequenzen verglichen werden.
Siehe auch: Kladistik
Algorithmen
Daten-clustering-Algorithmen können hierarchisch oder partitionierend sein, wobei man erstere noch in agglomerierende (bottom-up) oder unterteilende (top-down) Algorithmen unterteilt (vgl. Top-down und Bottom-up). Weiterhin unterscheidet man zwischen überwachten (supervised) und nicht-überwachten (unsupervised) Algorithmen. Außerdem gibt es modellbasierte Algorithmen, bei denen eine Annahme über die zugrundeliegende Verteilung der Daten gemacht wird (z. B. mixture-of-Gaussians model).
graphentheoretisch unterteilende hierarchisch agglomerierend Clusterverfahren Austausch partitionierend iterierte Minimaldistanz Optimierung
Zu den agglomerierenden Verfahren zählen
- Single Linkage
- Complete Linkage
- Average Linkage
- Centroid
- Median
- Ward
Ferner unterscheidet man zwischen "harten" und "weichen" Clusteringalgorithmen. Harte Methoden (z. B. K-Means, Spectral Clustering, Kernel PCA) ordnen jeden Datenpunkt genau einem Cluster zu, wohingegen bei weichen Methoden (z. B. EM-Algorithmus mit mixture-of-Gaussians model) jedem Datenpunkt für jeden Cluster eine Wahrscheinlichkeit zugeordnet wird mit der dieser Datenpunkt in diesem Cluster liegt. Weiche Methoden sind insbesondere dann nützlich wenn die Datenpunkte relativ homogen im Raum verteilt sind und die Cluster nur als Regionen mit erhöhter Datenpunktdichte in Erscheinung treten, d.h. wenn es z. B. fließende Übergänge zwischen den Clustern oder Hintergrundrauschen gibt (harte Methoden sind in diesem Fall unbrauchbar).
Je nach Algorithmus muss eine Distanzfunktion (z. B. beim k-means-Algorithmus) zur Bestimmung des Abstands zweier Elemente (d(a,b), zum Beispiel die euklidische Distanz) und/oder eine Methode zur Berechnung des Mittelpunktes oder Zentroiden eines Clusters (
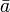 , zum Beispiel der Mittelwert) bekannt sein. Anstatt einer Distanzfunktion arbeiten einige Algorithmen auch mit einer Ähnlichkeitsfunktion (z. B. Spectral Clustering).
, zum Beispiel der Mittelwert) bekannt sein. Anstatt einer Distanzfunktion arbeiten einige Algorithmen auch mit einer Ähnlichkeitsfunktion (z. B. Spectral Clustering).Hierarchisches Clustern
Prinzip
Grundsätzlich lassen sich anhäufende Verfahren (agglomerative clustering) und teilende Verfahren (divisive clustering) unterscheiden. Bei den anhäufenden Verfahren, die in der Praxis häufiger eingesetzt werden, werden schrittweise einzelne Objekte zu Clustern und diese zu größeren Gruppen zusammengefasst, während bei den teilenden Verfahren größere Gruppen schrittweise immer feiner unterteilt werden. Die bei der hierarchischen Clusterung entstehende Baumstruktur wird in der Regel mit einem Dendrogramm visualisiert.
Beim Anhäufen der Cluster wird zunächst jedes Objekt als ein eigener Cluster mit einem Element aufgefasst. Nun werden in jedem Schritt die jeweils einander nächsten Cluster zu einem Cluster zusammengefasst. Das Verfahren kann beendet werden, wenn alle Cluster eine bestimmte Distanz zueinander überschreiten oder wenn eine genügend kleine Zahl von Clustern ermittelt worden ist. Es existieren verschiedene Distanzfunktionen d zur Bestimmung des Abstands zweier Cluster.
Distanzfunktionen
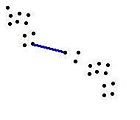 Single Linkage-
Single Linkage-
AbstandDer Abstand zweier Cluster A und B kann auf verschiedene Weisen definiert werden:
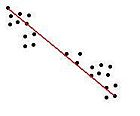 Complete Linkage-
Complete Linkage-
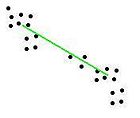
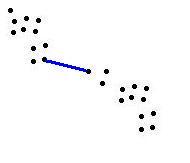
Abstand- Der minimale Abstand zweier Elemente aus den beiden Clustern (single linkage clustering)
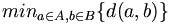
 Mittelwert-
Mittelwert-
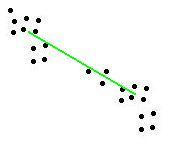
Abstand- Der maximale Abstand zweier Elemente aus den beiden Clustern (complete linkage clustering)
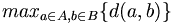
- Der durchschnittliche Abstand aller Elementpaare aus den beiden Clustern (average linkage clustering)
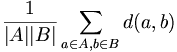
- Der durchschnittliche Abstand aller Elementpaare aus der Vereinigung von A und B (average group linkage)
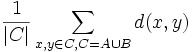
- Der Abstand der Mittelwerte der beiden Cluster (centroid method)
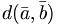
- Die Zunahme der Varianz beim Vereinigen von A und B (Ward’s method)
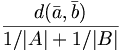
Weitere Methoden: Density Linkage, Uniform-Kernel, Wong’s Hybrid, EML, Flexible-Beta, McQuitty’s Similarity Analysis, Median
Partitionierende Clusterverfahren
k-means-Algorithmus
Beim k-means Algorithmus wird die Anzahl k von Clustern vor dem Start festgelegt. Eine Funktion zur Bestimmung des Zentrums eines Clusters muss bekannt sein.
Der Algorithmus läuft folgendermaßen ab:
- Initialisierung: (zufällige) Auswahl von k Clusterzentren
- Zuordnung: Jedes Objekt wird dem ihm am nächsten liegenden Clusterzentrum zugeordnet
- Neuberechnung: Es werden für jeden Cluster die Clusterzentren neu berechnet
- Wiederholung: Falls sich nun die Zuordnung der Objekte ändert, weiter mit Schritt 2, ansonsten Abbruch
Eigenheiten
- Der k-means-Algorithmus liefert für unterschiedliche Startpositionen der Clusterzentren möglicherweise unterschiedliche Ergebnisse
- Es kann sein, dass ein Cluster in einem Schritt leer bleibt und somit (mangels Berechenbarkeit eines Clusterzentrums) nicht mehr gefüllt werden kann.
- Ein optimales Clustering zu finden gehört zur Komplexitätsklasse NP. Der k-means Algorithmus findet nicht notwendigerweise die optimale Lösung, ist aber viel schneller.
Um diese Probleme zu umgehen, startet man den k-means-Algorithmus einfach neu in der Hoffnung, dass beim nächsten Lauf durch andere zufällige Clusterzentren ein anderes Ergebnis geliefert wird. Trotz der obigen theoretischen Unzulänglichkeiten gilt der k-means-Algorithmus als „quick’n’dirty“-Heuristik, weil er fast immer gute Resultate liefert.
Der isodata-Algorithmus kann als Spezialfall von k-means angesehen werden.
EM-Algorithmus
Die Idee des EM-Algorithmus basiert auf dem Clustern nach k-means. Grundvoraussetzung ist hier, dass alle Objekte als Vektoren der Dimension n dargestellt werden können. „n“ kann beliebig gewählt werden. Weiterhin muss eine Funktion bekannt sein, nach der der Mittelwert zweier solcher Vektoren berechnet werden kann. Wie bei k-means wird zu Beginn des Clustervorgangs eine beliebige, domänenspezifische Anzahl von Clustern vorgegeben, in die die Objekte eingeteilt werden sollen. Jeder dieser Cluster hat einen Mittelpunkt: Einen Vektor der Dimension n.
Der Clusteralgorithmus selbst durchläuft zwei Schritte:
- Expectation: Bestimme für jedes Objekt nach einer beliebigen Wahrscheinlichkeitsverteilung (z. B. die Normalverteilung), mit welcher Wahrscheinlichkeit es zu jedem der Cluster gehört und speichere diese Wahrscheinlichkeiten für alle Objekte und Cluster.
- Maximization: Bestimme anhand der ermittelten Zuordnungswahrscheinlichkeiten die Parameter neu, die die Cluster bestimmen (z. B. die Mittelwertvektoren).
Die Iteration wird abgebrochen, wenn entweder die Änderung der Likelihood der Daten gegeben die Clustern unter einen vorgegebenen Schwellenwert sinkt, oder die ebenfalls vorgegebene maximale Anzahl von Iterationen erreicht ist.
Im Gegensatz zu k-means wird damit eine „weiche“ Clusterzuordnung erreicht: Mit einer gewissen Wahrscheinlichkeit gehört jedes Objekt zu jedem Cluster. Jedes Objekt beeinflusst so die Parameter jedes Clusters entsprechend dieser Wahrscheinlichkeit. Der Erfolg des Algorithmus hängt stark von der gewählten Wahrscheinlichkeitsverteilung ab.
Spectral Clustering
Dieser Algorithmus wird häufig in der Bildverarbeitung eingesetzt, kann aber auch zum Clustern von Websuchergebnissen verwendet werden.
- Input: Adjazenzmatrix A, die die paarweisen Ähnlichkeiten der zu clusternden Objekte enthält
- Finde einen Schnitt durch diesen Graphen so, dass möglichst wenig Verbindungen zwischen ähnlichen Instanzen durchtrennt werden
- solange nicht die gewünschte Anzahl Clustern erreicht ist: zurück zu 2.
Maximum Margin Clustering
Problemstellung: Beim Clustering existieren keine Labels zu den Beispielen. Die Aufgabe ist es, ein Labeling der Instanzen zu finden, das den größten Abstand (margin) zwischen den Clustern ermöglicht.
Naiver Ansatz zur Lösung des Problems:
- Input: Eine Menge von ungelabelten Beispielen
- Finde eine mögliche Clusteraufteilung und bezeichne alle Beispiele eines Clusters mit dem gleichen Label.
- Trainiere einen Large Margin Classifier (z. B. Support Vector Machine) auf den so entstandenen gelabelten Beispielen und bestimme die Größe des Margins
- zurück zu 2, solange die ideale Clusteraufteilung nicht gefunden wurde.
Multiview Clustering
Übliche Clusteralgorithmen können nur in einem Vektorraum clustern. Der Multiviewansatz ermöglicht das parallele Clustern in verschiedenen Vektorräumen. Webseiten können z. B. im TF-IDF-Raum dargestellt werden. Dann wird jedem Eintrag im Featurevektor die Häufigkeit des Wortes im gegebenen Dokument zugewiesen. Andererseits können sie auch als Summe ihrer eingehenden Links aufgefasst werden – dann enthält jeder Eintrag im Featurevektor genau dann eine 1, wenn von der entsprechenden Quellseite ein Link auf die aktuelle Seite existiert. Kombiniert man diese beiden Views mittels Multiview Clustering, so sind die resultierenden Ergebnisse nachweisbar qualitativ besser als bei einfacher Konkatenation der Featurevektoren.
Ablauf des Algorithmus am Beispiel Webseiten:
- Initialisiere die Mittelwertvektoren eines k-Means Algorithmus auf Basis der TFIDF Vektoren
- Ordne die Instanzen entsprechend ihrer TFIDF Repräsentation dem ihnen am nächsten gelegenen Cluster zu
- Initialisiere die Mittelwertvektoren eines zweiten k-Means auf Basis der in 2 entstandenen Clusterzuordnungen und der Linkvektoren
- Ordne die Instanzen entsprechend ihren Linkvektoren dem ihnen am nächsten gelegenes Cluster zu
- zurück zu 1, solange sich die Zuordnung der Instanzen zu Clustern noch ändert.
Self-Organizing Maps
Eine andere Möglichkeit unüberwachten Lernens bieten Self-Organizing Maps.
Fuzzy Clustering
Objektmengen können Elemente enthalten, die aufgrund mehrdeutiger Datenbefunde für keines der ermittelten Cluster prototypisch sind und mehreren Clustern zugeordnet werden könnten. Beim Fuzzy-Clustering werden Objekte unscharf (also mit einem bestimmten Zugehörigkeitsgrad) auf Cluster verteilt. Im Spezialfall der Zugehörigkeit = 1 bzw. der Zugehörigkeit = 0 ist das Element einem Cluster vollständig bzw. überhaupt nicht zugehörig. Der bekannteste Fuzzy-Clustering Algorithmus ist der Fuzzy C-Means Algorithmus.
Graphentheoretische Cluster
GDBSCAN – Dichteverbundene Cluster
Grundlagen Bei dichtebasiertem Clustering werden Cluster als Objekte in einem d-dimensionalen Raum betrachtet, welche dicht beieinander liegen. Es bestehen weiterhin Gebiete in denen Objekte weniger dicht beieinander liegen.
Grundbegriffe
- Ein Objekt o ∈ O heißt Kernobjekt, wenn gilt: |Nε(o)| ≥ MinPts, wobei Nε(o) = {o’ ∈ O | dist(o, o’) ≤ ε}.
- Ein Objekt p ∈ O ist direkt dichte-erreichbar von q ∈ O bzgl. ε und MinPts, wenn gilt: p ∈ Nε(q) und q ist ein Kernobjekt in O.
- Ein Objekt p ist dichte-erreichbar von q, wenn es eine Kette von direkt erreichbaren Objekten zwischen q und p gibt.
- Zwei Objekte p und q sind dichte-verbunden, wenn sie beide von einem dritten Objekt o aus dichte-erreichbar sind.
- Ein Cluster C bzgl. ε und MinPts ist eine nicht-leere Teilmenge von O mit für die die folgenden Bedingungen erfüllt sind:
- Maximalität: ∀ p, q ∈ O: wenn p ∈ C und q dichte-erreichbar von p ist, dann ist auch q ∈ C.
- Verbundenheit: ∀ p, q ∈ C: p ist dichte-verbunden mit q.
Cliquen und Zusammenhangskomponenten
Zwei Extreme bei der Clusterung in Netzwerken bilden die Einteilung in Zusammenhangskomponenten (Single Link) und in Cliquen.
Siehe auch
Neuroinformatik, Künstliche Intelligenz, Statistik, Clusterkoeffizient, Netzwerkanalyse, Latent-Class-Analyse, Rekurrenzplot
Literatur
- Steffen Bickel and Tobias Scheffer, Multi-View Clustering. Proceedings of the IEEE International Conference on Data Mining, 2004
- Bortz, J. (1999), Statistik für Sozialwissenschaftler. (Kap. 16, Clusteranalyse). Berlin: Springer
- A. Dempster, N. Laird, and D. Rubin, Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society B 39, 1977
- Moosbrugger, H. & Frank, D. (1992). Clusteranalytische Methoden. Bern: Huber
- Shi, J., and J. Malik Normalized Cuts and Image Segmentation, in Proc. of IEEE Conf. on Comp. Vision and Pattern Recognition, Puerto Rico 1997
- Xu, L., Neufeld, J., Larson, B. and Schuurmans, D., Maximum margin clustering. To appear in Advances in Neural Information Processing Systems (NIPS*2004), 2004
- Klaus Backhaus, Bernd Erichson, Wulf Plinke, Rolf Weiber, Multivariate Analysemethoden. Springer
- Härdle, W.; Simar, L. Applied Multivariate Statistical Analysis, Springer, New York, 2003
- Ester, M. and Sander, J. Knowledge Discovery in Databases. Techniken und Anwendungen, Springer, Berlin, 2000
Weblinks
- RapidMiner: freie Open-Source Software für Knowledge Discovery und Data Mining inklusive zahlreichen Verfahren zur Clusteranalyse von der TU Dortmund
- Carrot²: Open-Source-Framework zum Bau von Suchmaschinen mit Clusteranalyse-Funktionen
- www.xclustering.de: Demonstration für das thematische Clustering von deutschsprachigen Suchresultaten aus Yahoo, MSN und der Wikipedia
- k-means-demo: Applet mit interaktiver Demo und Möglichkeit zum schrittweisen Ablaufen des Algorithmus
- Eine SPSS orientierte Einführung in die Clusteranalyse (engl.)
- Clusteranalyse von biologischen Populationsverteilungen im Detail, also Schritt für Schritt erklärt in der Diplomarbeit (Kapitel 2) „Untersuchung zur Zooplanktonökologie in der Nordsee – Clusteranalyse anhand von ZISCH-Daten“, frei erhältlich
- Clusteranalyse von psychologischen Einstellungsdaten auf Basis von Faktorwerten mit allgemeingültigen methodischen Erläuterungen, freier Download

Wikimedia Foundation.