- Einfügesort
-
Insertionsort (engl. insertion – das Einfügen, sort – sortieren) ist ein einfaches stabiles Sortierverfahren. Es ist weit weniger effizient als andere anspruchsvollere Sortierverfahren. Dafür hat es jedoch folgende Vorteile: Es ist einfach zu implementieren, effizient bei (ziemlich) kleinen Eingabemengen, effizient bei Eingabemengen, die schon vorsortiert sind, stabil (d. h. die Reihenfolge von schon sortierten Elementen ändert sich nicht) und minimal im Speicherverbrauch, da der Algorithmus ortsfest arbeitet. Der Algorithmus entnimmt der unsortierten Eingabefolge ein beliebiges (z. B. das erste) Element und fügt es an richtiger Stelle in die (anfangs leere) Ausgabefolge ein. Geht man hierbei in der Reihenfolge der ursprünglichen Folge vor, so ist das Verfahren stabil. Wird auf einem Array gearbeitet, so müssen die Elemente hinter dem neu eingefügten Element verschoben werden. Dies ist die eigentlich aufwändige Operation von Insertionsort, da das Finden der richtigen Einfügeposition über eine binäre Suche vergleichsweise effizient erfolgen kann.
Inhaltsverzeichnis
Problembeschreibung
Das Vorgehen ist mit der Sortierung eines Spielkartenblatts vergleichbar. Am Anfang liegen die Karten des Blatts verdeckt auf dem Tisch. Die Karten werden nacheinander aufgedeckt und an der korrekten Position in das Blatt, das in der Hand gehalten wird, eingefügt. Um die Einfügestelle für eine neue Karte zu finden wird diese sukzessive (von links nach rechts) mit den bereits einsortierten Karten des Blattes verglichen. Zu jedem Zeitpunkt sind die Karten in der Hand sortiert und bestehen aus den zuerst vom Tisch entnommenen Karten.
Eingabe
Eine Folge von n zu sortierenden Zahlen
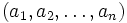 .
.Ausgabe
Umordnung
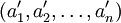 der Eingabefolge mit der Eigenschaft
der Eingabefolge mit der Eigenschaft 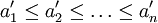 .
.Die Zahlen werden auch als Schlüssel (keys) bezeichnet; diese sind oft nur ein Bestandteil eines Datensatzes.
Implementierung
Pseudocode
Der folgende Pseudocode sortiert die Eingabefolge aufsteigend. Um eine absteigende Sortierung zu erreichen, ist der zweite Vergleich in Zeile 4 entsprechend zu ändern. Sei A die unsortierte Folge.
INSERTIONSORT(A) 1 for j = 2 to length(A) 2 do key = A[j] //Füge A[j] ein in die sortierte Folge A[1 .. j − 1] 3 i = j − 1 4 while i > 0 and A[i] > key 5 do A[i + 1] = A[i] 6 i = i − 1 7 A[i + 1] = keyDer Pseudocode für den Insertionsort-Algorithmus ist durch obige Prozedur INSERTIONSORT(A) gegeben, die als Eingabeparameter ein Feld A mit der zu sortierenden Folge erhält. Die Folge wird an Ort und Stelle (in place) sortiert. Nach Beendigung des Algorithmus enthält A die sortierte Folge.
Struktogramm
Im folgenden ein Nassi-Shneiderman-Diagramm (Struktogramm) des Insertionsort-Algorithmus. Die Bezeichner sind an obigen Pseudocode angelehnt.

Beispiel
Ausführung von Insertionsort auf Eingabefeld A[1..6]. Die Komponente, auf die der Index j zeigt, ist rot eingefärbt. Blau eingefärbte Felder liegen im bereits sortierten Teilfeld A[1..j − 1].
1 2 3 4 5 6 5 2 4 6 1 3 Das erste Element wird als sortiert angenommen und anschließend das zweite geprüft (j = 2).
1 2 3 4 5 6 5 2 4 6 1 3 1 2 3 4 5 6 2 5 4 6 1 3 Die 5 rutscht in der blauen sortierten Teilliste nach hinten und die 2 wird am Anfang dieser eingefügt. Damit sind die ersten beiden Elemente der Folge sortiert und das nächste Element wird überprüft (j = 3).
1 2 3 4 5 6 2 5 4 6 1 3 1 2 3 4 5 6 2 4 5 6 1 3 Bei j = 4 ist nichts weiter zu tun, da 6 bereits die richtige Position am Ende der sortierten Teilliste hat.
1 2 3 4 5 6 2 4 5 6 1 3 Im vorletzten Schritt wird die 1 ausgewählt und in die sortierte Liste eingefügt. Dabei rutschen alle bisherigen sortierten Elemente in der sortierten Liste um eins nach hinten (j = 5).
1 2 3 4 5 6 2 4 5 6 1 3 1 2 3 4 5 6 1 2 4 5 6 3 Im letzten Schritt wird die 3 an passender Position in die sortierte Teilliste gebracht (j = 6).
1 2 3 4 5 6 1 2 4 5 6 3 1 2 3 4 5 6 1 2 3 4 5 6 Nach dem Algorithmus sind alle Felder der Folge sortiert.
1 2 3 4 5 6 1 2 3 4 5 6 Komplexität
Die Anzahl der Vergleiche und Verschiebungen des Algorithmus ist von der Anordnung der Elemente in der unsortierten Eingangsfolge abhängig. Für den Average Case ist eine genaue Abschätzung der Laufzeit daher schwierig. Im Best Case, wenn das Eingabearray bereits sortiert ist, ist die Komplexität linear
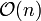 , d. h. sogar besser als bei den komplizierteren Verfahren (Quicksort, Mergesort, Heapsort etc.). Im Worst Case ist sie quadratisch
, d. h. sogar besser als bei den komplizierteren Verfahren (Quicksort, Mergesort, Heapsort etc.). Im Worst Case ist sie quadratisch 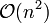 .
.Wenn zur Bestimmung der richtigen Position eines Elementes die binäre Suche benutzt wird, kann man die Anzahl der Vergleiche im Worst Case durch
abschätzen. Die Anzahl der Schiebeoperationen im Average Case beträgt
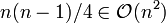 .
.
Der Worst Case ist ein absteigend sortiertes Array A, da jedes Element von seiner Ursprungsposition j bis auf die erste Arrayposition verschoben wird und dabei j − 1 Verschiebeoperationen nötig sind. Deren Gesamtanzahl beträgt somit
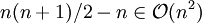 .
.
Weiterentwicklung
D. L. Shell schlug eine substanzielle Verbesserung dieses Algorithmus vor, die heute unter dem Namen Shellsort bekannt ist. Statt benachbarter Elemente werden Elemente, die durch eine bestimmte Distanz voneinander getrennt sind, verglichen. Diese Distanz wird bei jedem Durchgang verringert.
Weblinks
- http://www.inf.ethz.ch/~staerk/algorithms/SortAnimation.html Java Beispiele
- Weiteres Java-Applet zur Demonstration
- Beschreibung des Algorithmus und Java-Applet zur Simulation
- Insertionsort C, C++, C#, Java
Siehe auch: Liste von Algorithmen
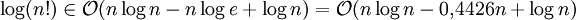
Wikimedia Foundation.