- Spracherkennung
-
Die Spracherkennung oder auch automatische Spracherkennung ist ein Teilgebiet der angewandten Informatik, der Ingenieurwissenschaften und der Computerlinguistik. Sie beschäftigt sich mit der Untersuchung und Entwicklung von Verfahren, die Automaten, insbesondere Computern, die gesprochene Sprache der automatischen Datenerfassung zugänglich macht. Die Spracherkennung ist zu unterscheiden von der Stimm- bzw. Sprechererkennung, einem biometrischen Verfahren zur Personenidentifikation. Allerdings ähneln sich die Realisierungen dieser Verfahren.
Inhaltsverzeichnis
Geschichtliche Entwicklung
Die Forschung an Spracherkennungssystemen begann in den 1960er Jahren, verlief damals allerdings weitestgehend erfolglos: Die von privaten Firmen entwickelten Systeme ermöglichten unter Laborbedingungen die Erkennung von einigen Dutzend Einzelwörtern. Dies lag einerseits an dem begrenzten Wissen in diesem neuen Forschungsgebiet, aber auch an den zur damaligen Zeit begrenzten technischen Möglichkeiten.
Erst Mitte der 1980er Jahre kam die Entwicklung weiter voran. In dieser Zeit entdeckte man, dass man durch Kontextprüfungen Homophone unterscheiden konnte. Indem man Statistiken über die Häufigkeit bestimmter Wortkombinationen erstellte und auswertete, konnte man bei ähnlich oder gleich klingenden Wörtern entscheiden, welches gemeint war. Diese so genannten Trigrammstatistiken wurden anschließend ein wichtiger Bestandteil aller Spracherkennungssysteme. 1984 stellte IBM ein erstes Spracherkennungssystem vor, das etwa 5.000 englische Einzelwörter erkennen konnte. Das System brauchte für einen Erkennungsvorgang jedoch mehrere Minuten Rechenzeit auf einem Großrechner. Fortschrittlicher war dagegen ein von Dragon Systems entwickeltes System: Dieses ließ sich auf einem tragbaren PC verwenden.
1991 stellte IBM erstmals auf der CeBIT ein Spracherkennungssystem vor, das 20.000 bis 30.000 deutsche Wörter erkennen konnte. Die Präsentation des TANGORA 4 genannten Systems musste jedoch in einem speziell abgeschirmten Raum stattfinden, da der Lärm der Messe das System sonst gestört hätte.
Ende 1993 stellte IBM das erste für den Massenmarkt entwickelte Spracherkennungssystem vor: Das IBM Personal Dictation System genannte System lief auf normalen PCs und kostete unter 1000 Dollar. Als es unter dem Namen IBM VoiceType Diktiersystem auf der CeBIT 1994 präsentiert wurde, stieß es auf hohes Interesse seitens der Besucher und der Fachpresse.
1997 erschienen für den PC-Endbenutzer sowohl die Software IBM ViaVoice (Nachfolger von VoiceType) als auch die Version 1.0 der Software Dragon NaturallySpeaking. 2004 gab IBM Teile seiner Spracherkennungsanwendungen als Open Source frei und sorgte damit für Aufsehen. Branchenkenner vermuteten als Grund taktische Maßnahmen gegen die Firma Microsoft, die ebenfalls in diesem Bereich tätig ist und in ihre PC-Betriebssysteme Windows Vista und Windows 7 eine Spracherkennungsfunktion integriert hat.
Während die Entwicklung von ViaVoice eingestellt wurde, entwickelte sich Dragon NaturallySpeaking zur gegenwärtig meistverbreiteten sprecherabhängigen Drittanbieter-Spracherkennungssoftware für Windows-PCs und wird von Nuance Communications seit 2011 in der Version 11.5 vertrieben.
Nuance hat 2008 mit dem Erwerb der Philips Speech Recognition Systems, Wien, auch die Rechte an dem Software Development Kit (SDK) SpeechMagic erlangt, welches insbesondere im Gesundheitsbereich Verbreitung gefunden hat. Für iMac-Personal Computer von Apple wurde von dem Unternehmen MacSpeech seit 2006 eine Drittanbieter-Spracherkennungssoftware unter dem Namen iListen vertrieben, die auf Philips-Komponenten basierte. 2008 wurde diese durch MacSpeech Dictate unter Verwendung der Kernkomponenten von Dragon NaturallySpeaking abgelöst und nach dem Erwerb von MacSpeech durch Nuance Communications 2010 in Dragon Dictate (Version 2.0) umbenannt.
Aktueller Stand
Derzeit kann grob zwischen zwei Arten der Spracherkennung unterschieden werden:
- Sprecherunabhängige Spracherkennung
- Sprecherabhängige Spracherkennung
Charakteristisch für die sprecherunabhängige Spracherkennung ist die Eigenschaft, dass der Benutzer ohne eine vorhergehende Trainingsphase sofort mit der Spracherkennung beginnen kann. Der Wortschatz ist jedoch auf einige tausend Wörter begrenzt.
Sprecherabhängige Spracherkenner müssen vom Benutzer vor der Verwendung auf die eigenen Besonderheiten der Aussprache trainiert werden. Ein Einsatz in Anwendungen mit häufig wechselnden Benutzern ist damit nicht möglich. Der Wortschatz ist im Vergleich sehr viel größer als der der sprecherunabhängigen Erkenner. So enthält etwa die aktuelle Version 11 der Software Dragon NaturallySpeaking rund 300.000 Wortformen. Zu unterscheiden ist ferner zwischen
- Front-End-Systemen und
- Back-End-Systemen.
In Front-End-Systemen (auch Online-Diktat genannt) erfolgt die Verarbeitung der Sprache und Umsetzung in Text direkt auf dem Computer des Benutzers, so dass er das Ergebnis praktisch ohne nennenswerte Zeitverzögerung ablesen kann. In Back-End-Systemen (auch Offline-Diktat oder Serverbasierte-Erkennung genannt) wird die Umsetzung hingegen auf einem entfernten Server durchgeführt, so dass der Text erst mit Verzögerung zur Verfügung steht. Solche Systeme sind insbesondere im medizinischen Bereich noch verbreitet. Neue Verbreitung können sie beim Einsatz auf Smartphones und ähnlichen Mobilgeräten finden. Ein Beispiel dafür ist die von Nuance Communications für BlackBerry, iPhone und iPad angebotene Applikation Dragon Dictation.[1]
Sprecherunabhängige Spracherkennung wird bevorzugt im technischen Einsatz verwendet, zum Beispiel in automatischen Dialogsystemen wie etwa einer Fahrplanauskunft. Überall dort, wo nur ein begrenzter Wortschatz verwendet wird, wird die sprecherunabhängige Spracherkennung mit Erfolg praktiziert. So erreichen Systeme zur Erkennung der gesprochenen englischen Ziffern von 0 bis 9 eine nahezu 100-%-Erkennungsquote.
Auch bei einem begrenzten Fachwortschatz werden im Einsatz von sprecherabhängiger Spracherkennung sehr hohe Erkennungsquoten erreicht. Wo allerdings kein begrenzter Wortschatz verwendet wird, wird keine vollständige Treffsicherheit mehr erreicht. Selbst eine Treffsicherheit von 95 Prozent ist indes zu gering, da zu viel nachgebessert werden muss (und sich die Fehler aufgrund einer oftmals verwendeten Trigramm-Statistik aufschaukeln können).
Zwischenzeitlich erreichen aktuelle Systeme beim Diktat von Fließtexten auf Personal Computern Erkennungsquoten von ca. 99 Prozent und erfüllen damit für viele Einsatzgebiete die Anforderungen der Praxis, z. B. für wissenschaftliche Texte, Geschäftskorrespondenz oder juristische Schriftsätze. An Grenzen stößt der Einsatz dort, wo der jeweilige Autor ständig neue, im Wörterbuch der Software nicht enthaltene Wörter und Wortformen benötigt, deren manuelle Hinzufügung zwar möglich, bei nur einmaligem Vorkommen in Texten desselben Sprechers aber nicht effizient ist. Daher profitieren z. B. Dichter und Journalisten weniger vom Einsatz der Spracherkennung als z. B. Ärzte und Rechtsanwälte.[2]
Neben der Größe des Wörterbuches spielt auch die Qualität der akustischen Aufnahme eine entscheidende Rolle. Bei Mikrofonen, die direkt vor dem Mund angebracht sind (zum Beispiel bei Headsets oder Telefonen) wird eine signifikant höhere Erkennungsgenauigkeit erreicht als bei weiter entfernten Raummikrofonen.
Siehe auch: Stenomaske
Wesentlichste Einflussfaktoren in der Praxis sind allerdings eine präzise Aussprache und das zusammenhängende Diktat von hinreichend langen Äußerungen, so dass das Sprachmodell optimal arbeiten kann.
Lippenlesen
Um die Erkennungsgenauigkeit noch weiter zu erhöhen, wird teils auch versucht, mithilfe einer Videokamera das Gesicht des Sprechers zu filmen und daraus die Lippenbewegungen abzulesen. Indem man diese Ergebnisse mit den Ergebnissen der akustischen Erkennung kombiniert, kann man gerade bei verrauschten Aufnahmen eine signifikant höhere Erkennungsquote erreichen.
Dies entspricht Beobachtungen bei der menschlichen Spracherkennung: Harry McGurk hatte 1976 festgestellt, dass auch Menschen aus der Lippenbewegung auf die gesprochene Sprache schließen (McGurk-Effekt).
Sprachausgabe
Da es sich bei Kommunikation mit menschlicher Sprache meist um einen Dialog zwischen zwei Gesprächspartnern handelt, findet man die Spracherkennung häufig in Verbindung mit Sprachsynthese. Auf diesem Weg können dem Benutzer des Systems akustische Rückmeldungen über den Erfolg der Spracherkennung und Hinweise über eventuell ausgeführte Aktionen gegeben werden. Auf die gleiche Weise kann der Benutzer auch zu einer erneuten Spracheingabe aufgefordert werden.
Problemstellung
Um zu verstehen, wie ein Spracherkennungssystem arbeitet, muss man sich zuerst über die Herausforderungen klar werden, die zu bewältigen sind.
Diskrete und kontinuierliche Sprache
Bei einem Satz in der Alltagssprache werden die einzelnen Wörter ohne wahrnehmbare Pause dazwischen ausgesprochen. Als Mensch kann man sich intuitiv an den Übergängen zwischen den Wörtern orientieren – frühere Spracherkennungssysteme waren dazu nicht in der Lage. Sie erforderten eine diskrete (unterbrochene) Sprache, bei der zwischen den Wörtern künstliche Pausen gemacht werden müssen.
Moderne Systeme sind jedoch auch fähig, kontinuierliche (fließende) Sprache zu verstehen.
Diskrete Sprache
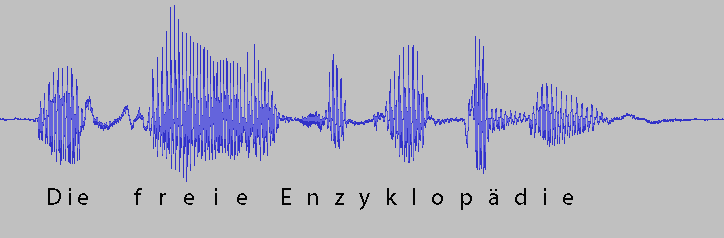
 Grafik des Satzes: „Die freie Enzyklopädie“, diskret ausgesprochen
Grafik des Satzes: „Die freie Enzyklopädie“, diskret ausgesprochen
Bei der diskreten Sprache erkennt man deutlich die Pausen zwischen den Wörtern, die länger und deutlicher ausfallen als die Übergänge zwischen den Silben innerhalb des Worts Enzyklopädie.
Kontinuierliche Sprache
 Grafik des Satzes: „Die freie Enzyklopädie“, kontinuierlich ausgesprochen
Grafik des Satzes: „Die freie Enzyklopädie“, kontinuierlich ausgesprochenBei der kontinuierlichen Sprache gehen die einzelnen Wörter ineinander über, es sind keine Pausen erkennbar.
Größe des Wortschatzes
Durch die Flexion, also die Beugung eines Wortes je nach grammatikalischer Funktion, entstehen aus Wortstämmen (Lexemen) eine Vielzahl von Wortformen. Dies ist für die Größe des Wortschatzes von Bedeutung, da alle Wortformen bei der Spracherkennung als eigenständige Wörter betrachtet werden müssen.
Die Größe des Wörterbuchs hängt stark von der Sprache ab. Zum einen haben durchschnittliche deutschsprachige Sprecher mit zirka 4000 Wörtern einen deutlich größeren Wortschatz als englischsprachige mit zirka 800 Wörtern. Außerdem ergeben sich durch die Flexion in der deutschen Sprache zirka zehnmal so viele Wortformen, während in der englischen Sprache nur zirka viermal so viele Wortformen entstehen.
Homophone
In vielen Sprachen gibt es Wörter oder Wortformen, die eine unterschiedliche Bedeutung haben, jedoch gleich ausgesprochen werden. So klingen die Wörter Meer und mehr zwar identisch, haben jedoch trotzdem nichts miteinander zu tun. Solche Wörter nennt man Homophone. Da ein Spracherkennungssystem im Gegensatz zum Menschen in der Regel kein Weltwissen hat, kann es die verschiedenen Möglichkeiten nicht anhand der Bedeutung unterscheiden.
Die Frage nach der Groß- oder Kleinschreibung fällt auch in diesen Bereich.
Formanten
Auf akustischer Ebene spielt insbesondere die Lage der Formanten eine Rolle: Die Frequenzanteile gesprochener Vokale konzentrieren sich typischerweise auf bestimmte unterschiedliche Frequenzen, die Formanten genannt werden. Für die Unterscheidung der Vokale sind insbesondere die zwei tiefsten Formanten von Bedeutung: Die tiefere Frequenz liegt im Bereich von 200 bis 800 Hertz, die höhere im Bereich von 800 bis 2400 Hertz. Über die Lage dieser Frequenzen lassen sich die einzelnen Vokale unterscheiden.
Konsonanten
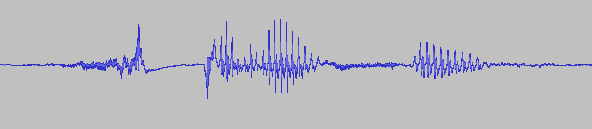
 „sprechen“ gesprochen, Original
„sprechen“ gesprochen, Original „p“ ausgeblendet
„p“ ausgeblendetKonsonanten sind vergleichsweise schwierig zu erkennen; einzelne Konsonanten (sogenannte Plosive) sind zum Beispiel nur durch den Übergang zu den benachbarten Lauten feststellbar, wie folgendes Beispiel zeigt:
Man erkennt, dass innerhalb des Wortes sprechen der Konsonant p (genauer: die Verschlussphase des Phonems p) faktisch nur Stille ist und lediglich durch die Übergänge zu den anderen Vokalen erkannt wird – das Entfernen bewirkt also keinen hörbaren Unterschied.
Andere Konsonanten sind durchaus an charakteristischen spektralen Mustern erkennbar. So zeichnen sich etwa der Laut s wie auch der Laut f durch einen hohen Energieanteil in höheren Frequenzbändern aus. Bemerkenswert ist, dass die für die Entscheidung dieser beiden Laute relevanten Informationen größtenteils außerhalb des in Telefonnetzen übertragenen Spektralbereichs (bis zirka 3,4 kHz) liegt. Dadurch ist es zu erklären, dass das Buchstabieren über Telefon ohne Verwendung eines speziellen Buchstabieralphabets auch in der Kommunikation zwischen zwei Menschen ausgesprochen mühselig und fehleranfällig ist.
Realisierung
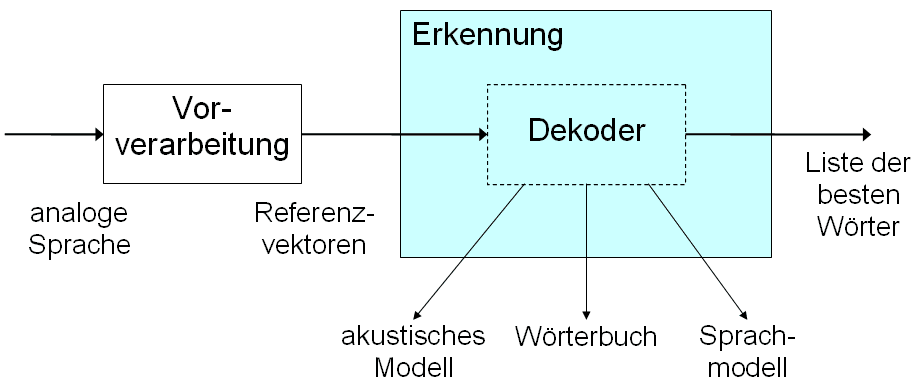
 Aufbau eines Spracherkennungssystems nach Alexander Waibel
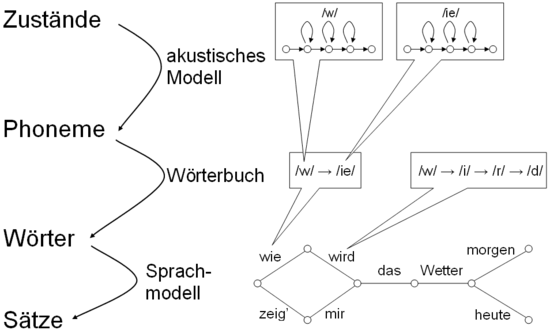
Aufbau eines Spracherkennungssystems nach Alexander WaibelEin Spracherkennungssystem besteht aus folgenden Bestandteilen: Einer Vorverarbeitung, die die analogen Sprachsignale in die einzelnen Frequenzen zerlegt. Anschließend findet die tatsächliche Erkennung mit Hilfe akustischer Modelle, Wörterbücher und Sprachmodellen statt.
Vorverarbeitung
Die Vorverarbeitung besteht im Wesentlichen aus den Schritten Abtastung, Filterung, Transformation des Signals in den Frequenzbereich und Erstellen des Merkmalsvektors.
Abtastung
Bei der Abtastung wird das diskrete Signal digitalisiert, also in eine elektronisch verarbeitbare Bitfolge zerlegt, um es einfacher weiterverarbeiten zu können.
Filterung
Die wichtigste Aufgabe des Arbeitsschrittes Filterung ist die Unterscheidung von Umgebungsgeräuschen wie Rauschen oder z. B. Motorengeräuschen und Sprache. Dazu wird zum Beispiel die Energie des Signals oder die Nulldurchgangsrate herangezogen.
Transformation
Für die Spracherkennung ist nicht das Zeitsignal, sondern das Signal im Frequenzbereich relevant. Dazu wird es mittels FFT transformiert. Aus dem Resultat, dem Frequenzspektrum, lassen sich die im Signal vorhandenen Frequenzanteile ablesen.
Merkmalsvektor
Zur eigentlichen Spracherkennung wird ein Merkmalsvektor erstellt. Dieser besteht aus von einander abhängigen oder unabhängigen Merkmalen, die aus dem digitalen Sprachsignal erzeugt werden. Dazu gehört neben dem schon erwähnten Spektrum vor allem das Cepstrum. Merkmalsvektoren lassen sich z. B. mittels einer zuvor zu definierenden Metrik vergleichen.
Cepstrum
Das Cepstrum wird aus dem Spektrum gewonnen, indem die FFT des logarithmierten Betrags-Spektrum gebildet wird. So lassen sich Periodizitäen im Spektrum erkennen. Diese werden erzeugt im menschlichen Vokaltrakt und durch die Stimmbandanregung. Die Periodizitäten durch die Stimmbandanregung überwiegen und sind daher im oberen Teil des Cepstrums zu finden, wohingegen der untere Teil die Stellung des Vokaltraktes abbildet. Dieser ist für die Spracherkennung relevant, daher fließen nur diese unteren Anteile des Cepstrums in den Merkmalsvektor ein. Da sich die Raumübertragunsfunktion - also die Veränderung des Signals z. B. durch Reflexionen an Wänden - zeitlich nicht verändert, lässt diese sich durch den Mittelwert des Cepstrums darstellen. Dieser wird deshalb häufig vom Cepstrum subtrahiert um Echos zu kompensieren. Ebenso ist zur Kompensation der Raumübertragungsfunktion die erste Ableitung des Cepstrum heranzuziehen, die ebenfalls in den Merkmalsvektor einfließen kann.
Erkennung
 Modell des Erkennungsprozesses
Modell des ErkennungsprozessesHidden-Markov-Modelle
Im weiteren Verlauf spielen Hidden-Markov-Modelle (HMM) eine wichtige Rolle. Diese ermöglichen es, die Phoneme zu finden, die am besten zu den Eingangssignalen passen. Dazu wird das akustische Modell eines Phonems in verschiedene Teile zerlegt: Den Anfang, je nach Länge unterschiedlich viele Mittelstücke und das Ende. Die Eingangssignale werden mit diesen gespeicherten Teilstücken verglichen und mit Hilfe des Viterbi-Algorithmus mögliche Kombinationen gesucht.
Für die Erkennung von unterbrochener (diskreter) Sprache (bei der nach jedem Wort eine Pause gemacht wird) reichte es aus, jeweils ein Wort zusammen mit einem Pausenmodell innerhalb des HMMs zu berechnen. Da die Rechenkapazität moderner PCs aber deutlich gestiegen ist, kann mittlerweile auch fließende (kontinuierliche) Sprache erkannt werden, indem größere Hidden Markov Modelle gebildet werden, die aus mehreren Wörtern und den Übergängen zwischen ihnen bestehen.
Neuronale Netze
Alternativ wurden auch schon Versuche unternommen, neuronale Netze für das akustische Modell zu verwenden. Mit Time Delay Neural Networks sollten dabei insbesondere die Veränderungen im Frequenzspektrum über den Zeitablauf hinweg zur Erkennung verwendet werden. Die Entwicklung hat durchaus positive Ergebnisse gebracht, wurde letztlich aber zugunsten der HMMs wieder aufgegeben.
Es gibt aber auch einen hybriden Ansatz, bei dem die aus der Vorverarbeitung gewonnenen Daten durch ein neuronales Netzwerk vor-klassifiziert werden, und die Ausgabe des Netzes als Parameter für die Hidden Markov Modelle genutzt werden. Dies hat den Vorteil, dass man ohne die Komplexität der HMMs zu erhöhen auch Daten von kurz vor und kurz nach dem gerade bearbeiteten Zeitraum nutzen kann. Außerdem kann man so die Klassifizierung der Daten und die kontextsensitive Zusammensetzung (Bildung von sinnvollen Wörtern/Sätzen) voneinander trennen.
Sprachmodell
Das Sprachmodell versucht anschließend, die Wahrscheinlichkeit bestimmter Wortkombinationen zu bestimmen und dadurch falsche oder unwahrscheinliche Hypothesen auszuschließen. Dazu kann entweder ein Grammatikmodell unter Verwendung Formaler Grammatiken oder ein statistisches Modell mit Hilfe von N-Grammen eingesetzt werden.
Eine Bi- oder Trigrammstatistik speichert die Auftrittswahrscheinlichkeit von Wortkombinationen aus zwei oder drei Wörtern (die in aktueller Software wie Dragon eingesetzte Quadgramm-Statistik entsprechend Wortkombinationen von vier Wörtern). Diese Statistiken werden aus großen Textkorpora (Beispieltexten) gewonnen. Jede von der Spracherkennung ermittelte Hypothese wird anschließend geprüft und ggf. verworfen, falls ihre Wahrscheinlichkeit zu gering ist. Dadurch können auch Homophone, also unterschiedliche Wörter mit identischer Aussprache unterschieden werden. Vielen Dank wäre also wahrscheinlicher als Fielen Dank, obwohl beides gleich ausgesprochen wird.
Mit Trigrammen sind im Vergleich zu Bigrammen theoretisch zutreffendere Schätzungen der Auftrittswahrscheinlichkeiten der Wortkombinationen möglich. Allerdings müssen die Beispieltext-Datenbanken, aus denen die Trigramme extrahiert werden, wesentlich größer sein als für Bigramme, denn es müssen sämtliche zulässigen Wortkombinationen aus drei Wörtern in statistisch signifikanter Anzahl darin vorkommen (d. h.: jede wesentlich mehr als einmal). Kombinationen von vier oder mehr Wörtern wurden lange nicht verwendet, weil sich im Allgemeinen keine Beispieltext-Datenbanken mehr finden lassen, die sämtliche Wortkombinationen in genügender Anzahl beinhalten. Eine Ausnahme bildet hier Dragon, welches seit der Version 9 auch Quadgramme verwendet - was die Erkennungsgenauigkeit in diesem System nochmals spürbar steigert.
Wenn Grammatiken verwendet werden, handelt es sich meist um kontextfreie Grammatiken. Dabei muss allerdings jedem Wort seine Funktion innerhalb der Grammatik zugewiesen werden. Deshalb werden solche Systeme meist nur für einen begrenzten Wortschatz und Spezialanwendungen verwendet, nicht aber in der gängigen Spracherkennungssoftware für PCs.
Evaluation
Die Güte eines Sprachererkennungssystems lässt sich mit verschiedenen Zahlen angeben. Neben Erkennungsgeschwindigkeit – meist als Echtzeitfaktor (EZF) angegeben – lässt sich die Erkennungsgüte als Wortakkuratheit oder Worterkennungsrate messen.
Spracherkennung für das Gesundheitswesen
Gerade in der Medizin werden zunehmend Spracherkennungssysteme bei der Erstellung von Befunden und Arztbriefen eingesetzt.[3] Ärzte müssen einen enormen Dokumentationsaufwand bewältigen, die erhöhte Berichtspflicht für Praxisärzte seit Einführung des EBM 2000plus (Deutschland) hat den Aufwand noch verstärkt.
Weltweiter Marktführer bei medizinischen Spracherkennungssystemen ist der Hersteller Nuance Communications mit den Systemen SpeechMagic und Dragon Medical. Daneben gibt es noch einige kleinere Unternehmen, die sich speziell auf den medizinischen Sektor konzentrieren und individuelle, auf den jeweiligen Benutzer zugeschnittene Vokabulare anbieten.
Weiterhin gibt es auch erste Anwendungen von Spracherkennungsystemen zur Bewertung der Verständlichkeit von pathologischer Sprache.
Vokabulare
Für die Integration von Spracherkennungssystemen gibt es bereits vordefinierte Vokabulare, die die Arbeit mit der Spracherkennung erleichtern sollen. Diese Vokabulare werden im Umfeld von SpeechMagic ConTexte und im Bereich von Dragon Fachvokabulare genannt. Je besser das Vokabular auf den vom Sprecher verwendeten Wortschatz und Diktierstil (Häufigkeit der Wortfolgen) angepasst ist, desto höher ist die Erkennungsgenauigkeit. Ein Vokabular beinhaltet neben dem sprecherunabhängigen Lexikon (Fach- und Grundwortschatz) auch ein individuelles Wortfolgemodell (Sprachmodell). Im Vokabular sind alle der Software bekannten Wörter in der Phonetik und Orthografie hinterlegt. Auf diese Weise wird ein gesprochenes Wort an seinem Klang durch das System erkannt. Wenn sich Wörter in Bedeutung und Schreibweise unterscheiden, aber gleich klingen, greift die Software auf das Wortfolgemodell zurück. In ihm ist die Wahrscheinlichkeit definiert, mit der bei einem bestimmten Benutzer ein Wort auf ein anderes folgt.
Siehe auch
Literatur
- Lawrence R. Rabiner und Ronald W. Schafer: Digital Processing of Speech Signals, 1978, ISBN 0-13-213603-1
- Alexander Waibel: Readings in Speech Recognition, 1990, ISBN 1-55860-124-4
- Lawrence R. Rabiner und Biing-Hwang Juang Juang: Fundamentals of Speech Recognition, 1993, ISBN 0-13-015157-2
- E.-G. Schukat-Talamazzini: Automatische Spracherkennung, 1995+2001, ISBN 3-528-15492-6
- Speech Recognition: Lehrbuch / Skript: 'An Introduction to Speech Recognition' von B. Plannerer, C++ Tutorial und MATLAB Beispiele (englisch)
Quellen
- ↑ http://itunes.apple.com/de/app/dragon-dictation/id341446764?mt=8
- ↑ http://www.faz.net/-01i41t
- ↑ „Digitales Diktat alleine macht keinen Sinn“, Interview mit Dr. Peter Gocke, Universitätsklinikum Hamburg Eppendorf
Weblinks
 Wiktionary: Spracherkennung – Bedeutungserklärungen, Wortherkunft, Synonyme, Übersetzungen
Wiktionary: Spracherkennung – Bedeutungserklärungen, Wortherkunft, Synonyme, Übersetzungen

Dieser Artikel wurde in die Liste der lesenswerten Artikel aufgenommen. Kategorien:- Wikipedia:Lesenswert
- Sprach-Interaktion
- Computerlinguistik
- Biometrie



Wikimedia Foundation.