- Informatik
-
Informatik ist die „Wissenschaft von der systematischen Verarbeitung von Informationen, besonders der automatischen Verarbeitung mit Hilfe von Digitalrechnern“ [1]. Historisch hat sich die Informatik einerseits aus der Mathematik entwickelt, andererseits durch die Entwicklung von Rechenanlagen aus der Elektrotechnik und der Nachrichtentechnik.
Inhaltsverzeichnis
- 1 Entwicklung der Informatik
- 2 Disziplinen der Informatik
- 3 Informatik und Recht
- 4 Der Mensch und Informatik
- 5 Siehe auch
- 6 Literatur
- 7 Einzelnachweise
- 8 Weblinks
Entwicklung der Informatik
Ursprung
Die Wurzeln der Informatik liegen in der Mathematik, der Physik und der Elektrotechnik (hier vor allem der Nachrichtentechnik).
Bereits Leibniz hatte sich mit binären Zahlendarstellungen beschäftigt. Gemeinsam mit der Booleschen Algebra, die zuerst 1847 von George Boole ausgearbeitet wurde, bilden sie die wichtigsten mathematischen Grundlagen späterer Rechensysteme. 1937 veröffentlicht Alan Turing seine Arbeit On Computable Numbers with an application to the Entscheidungsproblem, in welcher die nach ihm benannte Turingmaschine vorgestellt wird, ein mathematisches Maschinenmodell, das bis heute für die Theoretische Informatik von größter Bedeutung ist. Dem Begriff der Berechenbarkeit liegen bis heute universelle Modelle wie die Turing- oder Registermaschine zu Grunde, und auch die Komplexitätstheorie, die sich ab den 1960er Jahren zu entwickeln begann, greift bis in die Gegenwart auf Varianten dieser Modelle zurück.
Entwicklung der Informatik zur Wissenschaft
Nach einem internationalen Kolloquium in Dresden am 26. Februar 1968 setzte sich „Informatik“ als Bezeichnung für die Wissenschaft nach französischem und russischem Vorbild auch im deutschen Sprachraum durch. Die Bezeichnung „Computerwissenschaften“ ist weniger gebräuchlich. Im Wintersemester 1969/70 begann die Universität Karlsruhe (heute Karlsruher Institut für Technologie) als erste deutsche Hochschule mit der Ausbildung von Diplom-Informatikern. Wenige Jahre darauf gründeten sich die ersten Fakultäten für Informatik, nachdem bereits seit 1962 an der Purdue University ein Department of Computer Science bestand.
Informatikbewegungen
Die Gesellschaft für Informatik (GI) wurde 1969 gegründet und ist die größte Fachvertretung im deutschsprachigen Raum. International bedeutend sind vor allem die beiden großen amerikanischen Vereinigungen Association for Computing Machinery (ACM) seit 1947 und das Institute of Electrical and Electronics Engineers (IEEE) seit 1963. In Deutschland genießt vor allem der Chaos Computer Club (Gründung 1981) hohe Bekanntheit.
Rechenmaschinen – Vorläufer des Computers
 Ein japanischer Soroban
Ein japanischer Soroban
Als erste Vorläufer der Informatik jenseits der Mathematik, also als Vorläufer der angewandten Informatik, können die Bestrebungen angesehen werden, zwei Arten von Maschinen zu entwickeln: Solche, mit deren Hilfe mathematische Berechnungen ausgeführt oder vereinfacht werden können („Rechenmaschinen“), und solche, mit denen logische Schlüsse gezogen und Argumente überprüft werden können („Logische Maschinen“). Als einfache Rechengeräte leisten Abakus und später der Rechenschieber unschätzbare Dienste. 1641 konstruiert Blaise Pascal eine mechanische Rechenmaschine, die Additionen inklusive Überträgen durchführen kann. Nur wenig später stellt Gottfried Wilhelm Leibniz eine Rechenmaschine vor, die alle vier Grundrechenarten beherrscht. Diese Maschinen basieren auf ineinandergreifenden Zahnrädern. Einen Schritt in Richtung größerer Flexibilität geht ab 1838 Charles Babbage, der eine Steuerung der Rechenoperationen mittels Lochkarten anstrebt. Erst Herman Hollerith ist aufgrund der technischen Fortschritte ab 1886 in der Lage, diese Idee gewinnbringend umzusetzen. Seine auf Lochkarten basierenden Zählmaschinen kommen unter anderem bei der Auswertung einer Volkszählung in den USA zum Einsatz.
Die Geschichte der logischen Maschinen wird oft bis ins 13. Jahrhundert zurückverfolgt und auf Ramon Llull zurückgeführt. Auch wenn seine rechenscheibenähnlichen Konstruktionen, bei denen mehrere gegeneinander drehbare Scheiben unterschiedliche Begriffskombinationen darstellen konnten, mechanisch noch nicht sehr komplex waren, war er wohl derjenige, der die Idee einer logischen Maschine bekannt gemacht hat. Von diesem sehr frühen Vorläufer abgesehen verläuft die Geschichte logischer Maschinen eher sogar zeitversetzt zu jener der Rechenmaschinen: Auf 1777 datiert ein rechenschieberähnliches Gerät des dritten Earl Stanhope, dem zugeschrieben wird, die Gültigkeit von Syllogismen (im aristotelischen Sinn) zu prüfen. Eine richtige „Maschine“ ist erstmals in der Gestalt des „Logischen Pianos“ von Jevons für das späte 19. Jahrhundert überliefert. Nur wenig später wird die Mechanik durch elektromechanische und elektrische Schaltungen abgelöst. Ihren Höhepunkt erleben die logischen Maschinen in den 1940er und 1950er Jahren, zum Beispiel mit den Maschinen des englischen Herstellers Ferranti. Mit der Entwicklung universeller digitaler Computer nimmt – im Gegensatz zu den Rechenmaschinen – die Geschichte selbstständiger logischen Maschinen ein jähes Ende, indem die von ihnen bearbeiteten und gelösten Aufgaben zunehmend in Software auf genau jenen Computern realisiert werden, zu deren hardwaremäßigen Vorläufern sie zu zählen sind.
Entwicklung moderner Rechenmaschinen
- Siehe hierzu auch den Abschnitt: Der Siegeszug des elektronischen Digitalrechners im Artikel Computer
Eine der ersten größeren Rechenmaschinen ist die von Konrad Zuse erstellte, noch immer rein mechanisch arbeitende Z1 von 1937. Vier Jahre später realisiert Zuse seine Idee mittels elektrischer Relais: Die Z3 von 1941 verfügt als erster Computer bereits über eine Trennung von Befehls- und Datenspeicher und ein Ein-/Ausgabepult. Etwas später werden in England die Bemühungen zum Bau von Rechenmaschinen zum Knacken von deutschen Geheimbotschaften unter maßgeblicher Leitung von Alan Turing mit großem Erfolg vorangetrieben. Parallel entwickelte Howard Aiken mit Mark I (1944) den ersten Computer der USA, wo die weitere Entwicklung maßgeblich vorangetrieben wurde. Einer der Hauptakteure ist hier John von Neumann, nach dem die bis heute bedeutende Von-Neumann-Architektur benannt ist. 1946 erfolgt die Entwicklung des Röhrenrechners ENIAC, 1949 wird der EDSAC gebaut. Ab 1948 steigt IBM in die Entwicklung von Computern ein und steigt innerhalb von zehn Jahren zum Marktführer auf. Mit der Entwicklung der Transistortechnik und der Mikroprozessortechnik werden Computer von dieser Zeit an immer leistungsfähiger und preisgünstiger. Im Jahre 1982 öffnet die Firma Commodore schließlich mit dem C64 den Massenmarkt speziell für Heimanwender aber auch weit darüber hinaus.
Maschinensprachen
1956 beschreibt Noam Chomsky eine Hierarchie formaler Grammatiken, mit denen formale Sprachen und jeweils spezielle Maschinenmodelle korrespondieren. Diese Formalisierungen erlangen für die Entwicklung höherer Programmiersprachen große Bedeutung. Wichtige Meilensteine sind die Entwicklung von Fortran (erste höhere Programmiersprache, 1957), ALGOL (strukturiert/imperativ; 1958/1960/1968), LISP (funktional, 1959), COBOL (Programmiersprache für kaufmännische Anwendungen, 1959), Smalltalk (objektorientiert, 1971), Prolog (logisch, 1972) und SQL (Relationale Datenbanken, 1976). Einige dieser Sprachen stehen für typische Programmierparadigmen ihrer jeweiligen Zeit. Weitere über lange Zeit in der Praxis eingesetzte Programmiersprachen sind BASIC (seit 1960), C (seit 1970), Pascal (seit 1971), C++ (objektorientiert, generisch, um 1990), Java (objektorientiert, seit 1995) und C# (objektorientiert, um 2000). Sprachen und Paradigmenwechsel wurden von der Informatik-Forschung intensiv begleitet oder vorangetrieben.
Indessen schreibt nahezu jeder wichtige Teilbereich der Informatik seine eigene Geschichte, die im Einzelnen zu verfolgen den Rahmen dieses Abschnitts sprengen würde. Wie in anderen Wissenschaften auch, schreitet die Informatik mit zunehmender Nähe zur Gegenwart in Richtung einer immer größeren Spezialisierung fort.
Disziplinen der Informatik
Die Teildisziplinen in der Informatik

Die Informatik unterteilt sich in die Teilgebiete der Theoretischen Informatik, der Praktischen Informatik und der Technischen Informatik.
Die Anwendungen der Informatik in den verschiedenen Bereichen des täglichen Lebens sowie in anderen Fachgebieten, wie beispielsweise der Wirtschaftsinformatik, Geoinformatik, Medizininformatik, werden unter dem Begriff der Angewandten Informatik geführt. Auch die Auswirkungen auf die Gesellschaft werden interdisziplinär untersucht.

Die theoretische Informatik bildet die theoretische Grundlage für die anderen Teilgebiete. Sie liefert fundamentale Erkenntnisse für die Entscheidbarkeit von Problemen, für die Einordnung ihrer Komplexität und für die Modellierung von Automaten und Formalen Sprachen.
Auf diese Erkenntnisse stützen sich Disziplinen der Praktischen und der Technischen Informatik. Sie beschäftigen sich mit zentralen Problemen der Informationsverarbeitung und suchen anwendbare Lösungen.
Die Resultate finden schließlich Verwendung in der Angewandten Informatik. Diesem Bereich sind Hardware- und Software-Realisierungen zuzurechnen und damit ein Großteil des kommerziellen IT-Marktes. In den interdisziplinären Fächern wird darüber hinaus untersucht, wie die Informationstechnik Probleme in anderen Wissenschaftsgebieten lösen kann. Als Beispiel mag hier die Entwicklung von Geodatenbanken für die Geographie dienen, aber auch die Wirtschafts- oder Bioinformatik.
Theoretische Informatik
Die Theoretische Informatik beschäftigt sich mit der Theorie formaler Sprachen bzw. Automatentheorie, Berechenbarkeits- und Komplexitätstheorie, Graphentheorie, Kryptologie, Logik (u. a. Aussagenlogik und Prädikatenlogik), formaler Semantik und bietet Grundlagen für den Bau von Compilern von Programmiersprachen und die mathematische Formalisierung von Problemstellungen.
Automatentheorie und Formale Sprachen
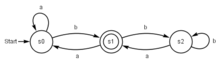
Automaten sind in der Informatik „gedachte Maschinen“, die sich nach bestimmten Regeln verhalten. Ein endlicher Automat hat eine endliche Menge von inneren Zuständen. Er liest ein „Eingabewort“ zeichenweise ein und führt bei jedem Zeichen einen Zustandsübergang durch. Zusätzlich kann er bei jedem Zustandsübergang ein „Ausgabesymbol“ ausgeben. Nach Ende der Eingabe kann der Automat das Eingabewort akzeptieren oder ablehnen.
Formale Sprachen eignen sich unter anderem zur Beschreibung von Programmiersprachen. Formale Sprachen lassen sich aber auch durch Automatenmodelle beschreiben, da die Menge aller von einem Automaten akzeptierten Wörter als formale Sprache betrachtet werden kann.
Kompliziertere Modelle, verfügen über einen Speicher, zum Beispiel Kellerautomaten oder die Turingmaschine, welche gemäß der Church-Turing-These alle durch Menschen berechenbaren Funktionen nachbilden kann.
 1-Band-Turingmaschine
1-Band-TuringmaschineBerechenbarkeitstheorie
Im Rahmen der Berechenbarkeitstheorie untersucht die theoretische Informatik, welche Probleme mit welchen Maschinen lösbar sind. Ein Rechnermodell oder eine Programmiersprache heißt turing-vollständig, wenn damit eine universelle Turingmaschine simuliert werden kann. Alle heute eingesetzten Computer und die meisten Programmiersprachen sind turing-vollständig, das heißt man kann damit dieselben Aufgaben lösen. Auch alternative Berechnungsmodelle wie der Lambda-Kalkül, WHILE-Programme, μ-rekursive Funktionen oder Registermaschinen stellten sich als turing-vollständig heraus. Aus diesen Erkenntnissen entwickelte sich die Church-Turing-These, die zwar formal nicht beweisbar ist, jedoch allgemein akzeptiert wird.
Den Begriff der Entscheidbarkeit kann man veranschaulichen als die Frage, ob ein bestimmtes Problem algorithmisch lösbar ist. Ein entscheidbares Problem ist zum Beispiel die Eigenschaft eines Texts, ein syntaktisch korrektes Programm zu sein. Ein nicht-entscheidbares Problem ist zum Beispiel die Frage, ob ein gegebenes Programm mit gegebenen Eingabeparametern jemals zu einem Ergebnis kommt, was als Halteproblem bezeichnet wird.
Komplexitätstheorie
Die Komplexitätstheorie befasst sich mit dem Ressourcenbedarf von algorithmisch behandelbaren Problemen auf verschiedenen mathematisch definierten formalen Rechnermodellen, sowie der Güte der sie lösenden Algorithmen. Insbesondere werden die Ressourcen „Laufzeit“ und „Speicherplatz“ untersucht und ihr Bedarf wird üblicherweise in der Landau-Notation dargestellt. In erster Linie werden die Laufzeit und der Speicherplatzbedarf in Abhängigkeit von der Länge der Eingabe notiert. Algorithmen, die sich höchstens durch einen konstanten Faktor in ihrer Laufzeit bzw. ihrem Speicherbedarf unterscheiden, werden durch die Landau-Notation der gleichen Klasse, d.h. einer Menge von Problemen mit äquivalenter vom Algorithmus für die Lösung benötigter Laufzeit, zugeordnet.
Ein Algorithmus, dessen Laufzeit von der Eingabelänge unabhängig ist, arbeitet „in konstanter Zeit“, man schreibt
 . Beispielsweise wird das Programm „gib das erste Element einer Liste zurück“ in konstanter Zeit arbeiten. Das Programm „prüfe, ob ein bestimmtes Element in einer unsortierten Liste der Länge n enthalten ist“ braucht „lineare Zeit“, also
. Beispielsweise wird das Programm „gib das erste Element einer Liste zurück“ in konstanter Zeit arbeiten. Das Programm „prüfe, ob ein bestimmtes Element in einer unsortierten Liste der Länge n enthalten ist“ braucht „lineare Zeit“, also  , denn die Eingabeliste muss schlimmstenfalls genau einmal komplett gelesen werden.
, denn die Eingabeliste muss schlimmstenfalls genau einmal komplett gelesen werden.Die Komplexitätstheorie liefert bisher fast nur obere Schranken für den Ressourcenbedarf von Problemen, denn Methoden für exakte untere Schranken sind kaum entwickelt und nur von wenigen Problemen bekannt (so zum Beispiel für die Aufgabe, eine Liste von Werten mit Hilfe einer gegebenen Ordnungsrelation durch Vergleiche zu sortieren, die untere Schranke Ω(nlog(n))). Dennoch gibt es Methoden besonders schwierige Probleme als solche zu klassifizieren, wobei die Theorie der NP-Vollständigkeit eine zentrale Rolle spielt. Demnach ist ein Problem besonders schwierig, wenn man durch dessen Lösung auch automatisch die meisten anderen natürlichen Probleme lösen kann, ohne dafür wesentlich mehr Ressourcen zu verwenden.
Die größte offene Frage in der Komplexitätstheorie ist die Frage, ob P gleich NP ist. Das Problem ist eines der Millennium-Probleme, die vom Clay Mathematics Institute mit einer Million US Dollar ausgeschrieben sind. Wenn P nicht gleich NP ist, können NP-vollständige Probleme nicht effizient gelöst werden können.
Praktische Informatik
Die Praktische Informatik beschäftigt sich mit der Lösung von konkreten Problemen und deren Umsetzung (Implementierung) in Form von Computerprogrammen. Sie liefert auch die grundlegenden Konzepte zur Lösung von Standardaufgaben, wie die Speicherung und Verwaltung der Informationen mittels Datenstrukturen. Einen wichtigen Stellenwert haben dabei die Algorithmen, die Musterlösungen für häufige oder schwierige Aufgaben bereitstellen. Beispiele dafür sind die Sortieralgorithmen und die schnelle Fourier-Transformation.
Eines der zentralen Themen der praktischen Informatik ist die Softwaretechnik. Sie beschäftigt sich mit der systematischen Erstellung von Software. Es werden auch Konzepte und Lösungsvorschläge für große Softwareprojekte entwickelt, die einen wiederholbaren Prozess von der Idee bis zur fertigen Software erlauben sollen.
C-Programmcode Maschinencode (schematisch) /** * Berechnung des ggT zweier Zahlen * nach dem Euklidischen Algorithmus */ int ggt(int zahl1, int zahl2) { int temp; while(zahl2 != 0) { temp = zahl1%zahl2; zahl1 = zahl2; zahl2 = temp; } return zahl1; }
→ Compiler → ···
0010 0100 1011 0111
1000 1110 1100 1011
0101 1001 0010 0001
0111 0010 0011 1101
0001 0000 1001 0100
1000 1001 1011 1110
0001 0011 0101 1001
0111 0010 0011 1101
0001 0011 1001 1100
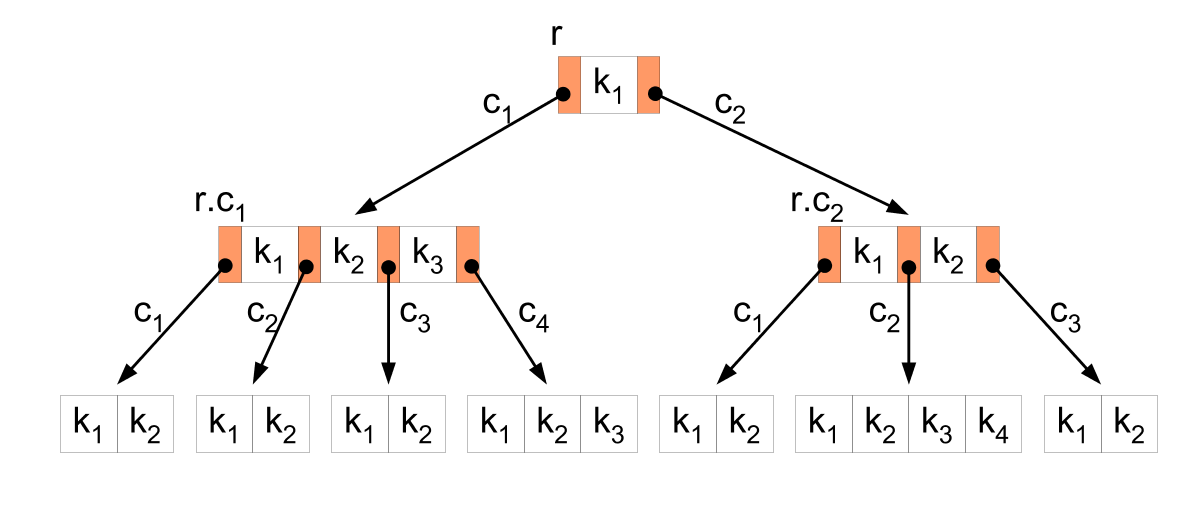
···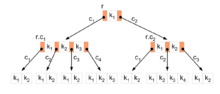 Skizze eines B-Baums
Skizze eines B-BaumsDie Praktische Informatik stellt auch die Werkzeuge zur Softwareentwicklung bereit. So werden Compiler für die Programmiersprachen wie Visual Basic, Java, Delphi oder C++ entwickelt. Compiler sind selbst Computerprogramme, die eine Computersprache in eine andere übersetzen. Sie erlauben es also einem Programmierer in einer für Menschen leichter verständlichen Sprache zu arbeiten. Ein Compiler übersetzt das Programm später in Maschinencode, der sehr „natürlichen“ Sprache des Computers.
Nur durch die Grundlage der formalen Sprachen wurde die effiziente Entwicklung von Compilern möglich. Übersetzer werden auch an vielen anderen Stellen in der Informatik verwendet. Zum Beispiel beim Übersetzen von HTML-Code in ein gut lesbares Dokument.
Ein Beispiel für den Einsatz von Datenstrukturen ist der B-Baum, der in Datenbanken und Dateisystemen das schnelle Suchen in großen Datenbeständen erlaubt.
Technische Informatik
Die Technische Informatik befasst sich mit den hardwareseitigen Grundlagen der Informatik wie etwa der Mikroprozessortechnik, Rechnerarchitekturen und verteilten Systemen. Damit stellt sie ein Bindeglied zur Elektrotechnik dar.
Die Rechnerarchitektur ist die Wissenschaft, die Konzepte für den Bau von Computern erforscht. Hier wird das Zusammenspiel von Mikroprozessor, Arbeitsspeicher sowie Controller und Peripherie definiert und verbessert. Das Forschungsgebiet orientiert sich dabei sowohl an den Anforderungen der Software als auch an den Möglichkeiten, die sich über die Weiterentwicklung von Integrierten Schaltkreisen ergeben.
 Heimrouter
HeimrouterEin weiteres wichtiges Gebiet ist die Rechnerkommunikation. Diese ermöglicht den elektronischen Datenaustausch zwischen Computern und stellt damit die technische Grundlage des Internets dar. Neben der Entwicklung von Routern, Switches oder einer Firewall, gehört auch die Entwicklung der Softwarekomponenten, die zum Betrieb dieser Geräte nötig ist, zur Rechnerkommunikation. Insbesondere gehört die Definition und Standardisierung der Netzwerkprotokolle, wie TCP, HTTP oder SOAP zur Rechnerkommunikation. Die Protokolle sind dabei die Sprachen, in denen Computer miteinander „reden“.
Während die Rechnerkommunikation die Kommunikation auf Protokollebene regelt, stellt die Wissenschaft der Verteilten Systeme, den Zusammenschluss von Computern im Großen dar. Hier regeln Prozesse die Zusammenarbeit von einzelnen Systemen in einem Verbund (Cluster). Schlagworte in diesem Zusammenhang sind beispielsweise Grid-Computing und Middleware.
Informatik in interdisziplinären Wissenschaften
Unter dem Sammelbegriff angewandte Informatik "fasst man das Anwenden von Methoden der Kerninformatik in anderen Wissenschaften ... zusammen"[1]. Rund um die Informatik haben sich einige interdisziplinäre Teilgebiete und Forschungsansätze entwickelt, teilweise zu eigenen Wissenschaften. Beispiele:
Ingenieurinformatik, Maschinenbauinformatik
Die Ingenieurinformatik, englisch auch als Computational Engineering Science bezeichnet, ist eine interdisziplinäre Lehre an der Schnittstelle zwischen den Ingenieurwissenschaften, der Mathematik und der Informatik an den Fachbereichen Elektrotechnik, Maschinenbau, Verfahrenstechnik, Systemtechnik.
Die Maschinenbauinformatik beinhaltet im Kern die virtuelle Produktentwicklung (Produktionsinformatik) mittels Computervisualistik, sowie die Automatisierungstechnik.Wirtschaftsinformatik, Informationsmanagement
Die Wirtschaftsinformatik (englisch (business) information systems, auch management information systems) ist eine „Schnittstellen-Disziplin“ zwischen der Informatik und den Wirtschaftswissenschaften, besonders der Betriebswirtschaftslehre. Sie hat sich durch ihre Schnittstellen zu einer eigenständigen Wissenschaft entwickelt. Ein Schwerpunkt der Wirtschaftsinformatik liegt auf der Abbildung von Geschäftsprozessen und der Buchhaltung in relationalen Datenbanksystemen und Enterprise-Resource-Planning-Systemen. Das Information Engineering der Informationssysteme und das Informationsmanagement spielen im Rahmen der Wirtschaftsinformatik eine gewichtige Rolle.
Medieninformatik
Die Medieninformatik hat die Schnittstelle zwischen Mensch und Maschine als Schwerpunkt und befasst sich mit der Verbindung von Informatik, Psychologie, Arbeitswissenschaft, Medientechnik, Mediengestaltung und Didaktik.
Computerlinguistik
In der Computerlinguistik wird untersucht, wie natürliche Sprache mit dem Computer verarbeitet werden kann. Sie ist ein Teilbereich der Künstlichen Intelligenz, aber auch gleichzeitig Schnittstelle zwischen Angewandter Linguistik und Angewandter Informatik. Verwandt dazu ist auch der Begriff der Kognitionswissenschaft, die einen eigenen interdisziplinären Wissenschaftszweig darstellt, der u. a. Linguistik, Informatik, Philosophie, Psychologie und Neurologie verbindet. Anwendungsgebiete der Computerlinguistik sind die Spracherkennung und -synthese, automatische Übersetzung in andere Sprachen und Informationsextraktion aus Texten.
Umweltinformatik, Geoinformatik
Die Umweltinformatik beschäftigt sich interdisziplinär mit der Analyse und Bewertung von Umweltsachverhalten mit Mitteln der Informatik. Schwerpunkte sind die Verwendung von Simulationsprogrammen, Geographische Informationssysteme (GIS) und Datenbanksysteme.
Die Geoinformatik (englisch geoinformatics) ist die Lehre des Wesen und der Funktion der Geoinformation und ihrer Bereitstellung in Form von Geodaten und mit den darauf aufbauenden Anwendungen auseinander. Sie bildet die wissenschaftliche Grundlage für Geoinformationssysteme (GIS). Allen Anwendungen der Geoinformatik gemeinsam ist der Raumbezug und fallweise dessen Abbildung in kartesische räumliche oder planare Darstellungen im Bezugssystem.Bioinformatik, Biodiversitätsinformatik
Die Bioinformatik (englisch bioinformatics, auch computational biology) befasst sich mit den informatischen Grundlagen und Anwendungen der Speicherung, Organisation und Analyse von biologischen Daten. Die ersten reinen Bioinformatikanwendungen wurden für die DNA-Sequenzanalyse entwickelt. Dabei geht es primär um das schnelle Auffinden von Mustern in langen DNA-Sequenzen und die Lösung des Problems, wie man zwei oder mehr ähnliche Sequenzen so übereinander legt und gegeneinander ausrichtet, dass man eine möglichst optimale Übereinstimmung erzielt (sequence alignment). Mit der Aufklärung und weitreichenden Funktionsanalyse verschiedener vollständiger Genome (z. B. des Fadenwurms Caenorhabditis elegans) verlagert sich der Schwerpunkt bioinformatischer Arbeit auf Fragestellungen der Proteomik, wie z. B. dem Problem der Proteinfaltung und Strukturvorhersage, also der Frage nach der Sekundär- oder Tertiärstruktur bei gegebener Aminosäuresequenz. Die Biodiversitätsinformatik umfasst die Speicherung und Verarbeitung von Informationen zur biologischen Vielfalt. Während die Bioinformatik sich mit Nucleinsäuren und Proteinen beschäftigt, sind die Objekte der Biodiversitätsinformatik Taxa, biologische Sammlungsbelege und Beobachtungsdaten.
Chemoinformatik
Die Chemoinformatik (engl. chemoinformatics, cheminformatics oder chemiinformatics) bezeichnet einen Wissenschaftszweig, der das Gebiet der Chemie mit Methoden der Informatik verbindet und umgekehrt. Sie beschäftigt sich mit der Suche im chemischen Raum welcher aus virtuellen (in silico) oder realen Molekülen besteht. Die Größe des chemischen Raumes wird auf etwa 1062 Moleküle geschätzt und ist weit größer als die Menge der bisher real synthetisierten Moleküle. Somit lassen sich unter Umständen Millionen von Molekülen mit Hilfe solcher Computer-Methoden in silico testen, ohne diese explizit mittels Methoden der Kombinatorischen Chemie oder Synthese im Labor erzeugen zu müssen.
Andere Informatikdisziplinen
Weitere Schnittstellen der Informatik zu anderen Disziplinen gibt es in der Informationswirtschaft, Medizinischen Informatik, Pflegeinformatik und der Rechtsinformatik, Informationsmanagement (Verwaltungsinformatik, Betriebsinformatik), Architekturinformatik (Bauinformatik) sowie der Agrarinformatik, Sozialinformatik, Archäoinformatik, Sportinformatik, sowie neue interdisziplinäre Richtungen wie beispielsweise das Neuromorphic Engineering. Die Zusammenarbeit mit der Mathematik oder der Elektrotechnik wird aufgrund der Verwandtschaft nicht als interdisziplinär bezeichnet.
Künstliche Intelligenz
 Eine Kohonenkarte beim Lernen
Eine Kohonenkarte beim LernenDie Künstliche Intelligenz (KI) ist ein großes Teilgebiet der Informatik mit starken Einflüssen aus Logik, Linguistik, Neurophysiologie und Kognitionspsychologie. Dabei unterscheidet sich die KI in der Methodik zum Teil erheblich von der klassischen Informatik. Statt eine vollständige Lösungsbeschreibung vorzugeben, wird in der Künstlichen Intelligenz die Lösungsfindung dem Computer selbst überlassen. Ihre Verfahren finden Anwendung in Expertensystemen, in der Sensorik und Robotik.
Im Verständnis des Begriffs „Künstliche Intelligenz“ spiegelt sich oft die aus der Aufklärung stammende Vorstellung vom Menschen als Maschine wider, dessen Nachahmung sich die so genannte „starke KI“ zum Ziel setzt: eine Intelligenz zu erschaffen, die wie der Mensch nachdenken und Probleme lösen kann und die sich durch eine Form von Bewusstsein beziehungsweise Selbstbewusstsein sowie Emotionen auszeichnet.
Die Umsetzung dieses Ansatzes erfolgte durch Expertensysteme, die im Wesentlichen die Erfassung, Verwaltung und Anwendung einer Vielzahl von Regeln zu einem bestimmten Gegenstand (daher „Experten“) leisten.
Im Gegensatz zur starken KI geht es der „schwachen KI“ darum, konkrete Anwendungsprobleme zu meistern. Insbesondere sind dabei solche Anwendungen von Interesse, zu deren Lösung nach allgemeinem Verständnis eine Form von „Intelligenz“ notwendig scheint. Letztlich geht es der schwachen KI somit um die Simulation intelligenten Verhaltens mit Mitteln der Mathematik und der Informatik; es geht ihr nicht um Schaffung von Bewusstsein oder um ein tieferes Verständnis der Intelligenz. Ein Beispiel aus der schwachen KI ist die Fuzzylogik.
Neuronale Netze gehören ebenfalls in diese Kategorie – seit Anfang der 1980er Jahre analysiert man unter diesem Begriff die Informationsarchitektur des (menschlichen oder tierischen) Gehirns. Die Modellierung in Form künstlicher neuronaler Netze illustriert, wie aus einer sehr einfachen Grundstruktur eine komplexe Mustererkennung geleistet werden kann. Gleichzeitig wird deutlich, dass diese Art von Lernen nicht auf der Herleitung von logisch oder sprachlich formulierbaren Regeln beruht – und somit etwa auch die besonderen Fähigkeiten des menschlichen Gehirns innerhalb des Tierreichs nicht auf einen regel- oder sprachbasierten „Intelligenz“-Begriff reduzierbar sind. Die Auswirkungen dieser Einsichten auf die KI-Forschung, aber auch auf Lerntheorie, Didaktik und andere Gebiete werden noch diskutiert.
Während die starke KI an ihrer philosophischen Fragestellung bis heute scheiterte, sind auf der Seite der schwachen KI Fortschritte erzielt worden.
Informatik und Recht
Ein Softwarepatent ist ein Patent auf eine Methode zur Programmierung oder ein Verfahren zur Verwendung eines Computers. Eine allgemein akzeptierte genaue Definition des Begriffs hat sich bisher noch nicht etabliert. Befürworter von Softwarepatenten sind etwa Unternehmen, die ihre Produkte gegen Nachahmung schützen wollen. Sie argumentieren, der Sinn von Softwarepatenten sei (wie bei „normalen“ Patenten auch), die Entwicklungskosten der Produkte in einer kurzen „Monopolphase“ wieder hereinzuholen. Gegner führen an, Algorithmen und Softwaretechnologien seien – anders als technische Erfindungen – ähnlich wie mathematische Erkenntnisse als Wissen einzuordnen und deshalb prinzipiell nicht schützbar. Außerdem seien die Produktzyklen im Computerbereich ungleich kürzer als in anderen Branchen, deswegen bedeute ein Softwarepatent einen unfair langen Stillstand des Wettbewerbes und werde vorwiegend zur Monopolisierung von Märkten verwendet.
Daneben gibt es Organisationen und Vereinigungen, die sich für freie Software einsetzen. Am bekanntesten sind das GNU-Projekt und die Free Software Foundation, die von Richard Stallman ins Leben gerufen wurden. Stallman entwickelte Lizenzen für freie Software und freie Dokumentation, unter welchen viele Projekte, wie auch die Wikipedia, entwickelt werden.
Der Mensch und Informatik
Rolle der Informatik in der Gesellschaft
Die Informatik hat in praktisch allen Bereichen des modernen Lebens Einzug gehalten. Offensichtlich wird dies durch den enormen Einfluss des Internets verstärkt. Die vielfältige, insbesondere weltweite, Vernetzung revolutionierte die Telekommunikation und die Informationsverarbeitung in den Unternehmen, die Logistik, die Medien aber auch praktisch alle privaten Haushalte. Weniger offensichtlich, aber allgegenwärtig ist die Informatik in Haushaltsgeräten wie Videorekordern oder Spülmaschinen, in denen eingebettete Systeme die mehr oder weniger intelligente Steuerung übernehmen.
2006 war in Deutschland Jahr der Informatik. Ziel des Informatikjahres war es, das Bewusstsein für die zahlreichen Möglichkeiten der Informatik zu schärfen und die Bedeutung der Informatik als Faktor für die wirtschaftliche Entwicklung Deutschlands zu veranschaulichen. Mit den Themen Mobilität, Sicherheit, Gesundheit, Wohnen, Sport, Kommunikation, Kultur und Entertainment sollte beispielhaft gezeigt werden, wo und wie sehr die Informatik im Alltag präsent ist.Mit der zunehmenden Durchdringung aller Lebensbereiche mit IKT und Computern (Informatisierung), sowie der wachsenden Vernetzung der Menschen über das Internet verwandelt sich die Gesellschaft in eine Informationsgesellschaft.
Vorteile der Informatik
Computer können große Datenmengen in kurzer Zeit verwalten, sichern, austauschen und verarbeiten. Um dieses zu ermöglichen, ist die Interaktion komplexer Hardware- und Softwaresysteme nötig, die auch das wesentliche Forschungsgebiet der Informatik darstellen. Als Beispiel mag die Wikipedia selbst dienen, in der 50.000 Anwender und Millionen von Besuchern täglich tausende Artikel suchen, lesen und bearbeiten.
Die Stärken von Computersystemen liegen darin, schematische Berechnungen auf großen Datenmengen mit hoher Geschwindigkeit und Genauigkeit ausführen zu können. Im Gegensatz dazu basieren viele scheinbar alltägliche Intelligenzleistungen des Menschen jedoch auf kognitiven Leistungen, die bis heute von Computern nur recht schlicht erbracht werden können. Als Beispiel sei hier das Erkennen von Gesichtern oder das Fällen von Entscheidungen bei unsicherer Wissensbasis genannt. Derartige Prozesse werden von der Künstlichen Intelligenz untersucht. In einzelnen Teildisziplinen konnten dabei bereits beachtliche Ergebnisse erzielt werden. Von einer umfassenden Nachahmung menschlicher Intelligenz kann dabei jedoch noch nicht gesprochen werden.
Nachteile der Informatik
 Joseph Weizenbaum in Berlin (2005)
Joseph Weizenbaum in Berlin (2005)Es gibt Kritiker, darunter Informatiker wie Joseph Weizenbaum, die zu einem sorgsameren Umgang mit moderner Technik und dem Computer mahnen. Weizenbaum schrieb in den 1960ern das Computerprogramm ELIZA, mit dem er die Verarbeitung natürlicher Sprache durch einen Computer demonstrieren wollte; ELIZA wurde als Meilenstein der „künstlichen Intelligenz“ gefeiert und sollte menschliche Psychologen bald ablösen. Weizenbaum war entsetzt über die Wirkung seines relativ einfachen Programms, das nie zum Ersetzen eines Therapeuten konzipiert gewesen war, und wurde durch dieses Schlüsselerlebnis zum Gesellschafts- und Medienkritiker. Der Bezeichnung als Computerkritiker widersprach er mit der Aussage „Ich bin kein Computerkritiker, Computer können mit Kritik nichts anfangen. Nein, ich bin Gesellschaftskritiker.“ Weizenbaum erläutert seine aktuelle Kritik an dem Glauben, Informatik sei wertfrei, in dem 2010 veröffentlichten Dokumentarfilm Plug & Pray.[2]
Die weite Verwendung von Computern führt in der heutigen Zeit zu einer breiten öffentlichen wie wissenschaftlichen Diskussion über die Wirkungen auf die Sozialisation und das Lernverhalten, insbesondere von Kindern und Jugendlichen. Es herrscht weitgehender Konsens, dass es Effekte gibt, allerdings sind Untersuchungen methodisch schwierig oder kommen zu widersprüchlichen Ergebnissen.
Einfluss auf die Privatsphäre der Menschen
In der Informationsgesellschaft entstehen neue gesellschaftliche Probleme, die in der Öffentlichkeit oft kontrovers und sehr emotional diskutiert werden. Eines dieser Themen ist der Schutz der Privatsphäre des Computerbenutzers, der Datenschutz. Durch die Vernetzung ist es nicht nur Benutzern möglich, schnell beliebige Informationen im Internet abzufragen. Umgekehrt wird auch das Ausspähen von persönlichen Informationen durch Behörden, Unternehmen und Kriminellen ermöglicht. Ziel ist es zum einen Verhaltensweisen von Kunden bei Onlinekäufen zu sammeln, aber auch den persönlichen E-Mail-Verkehr abzuhören, wie es amerikanische Geheimdienste tun, oder Zugangsdaten zu Banken und Kreditkarten auszuspähen.
Hier hat ein gegenseitiges Aufrüsten stattgefunden, auf der Anwenderseite werden persönliche Daten über Verschlüsselung gegen unbefugten Zugriff gesichert, während auf der anderen Seite mittels Cookies, Spyware oder Phishing versucht wird, die Schutzmechanismen auszuhebeln.
Unternehmen suchen gezielt über Data-Mining nach typischen Verhaltensweisen von Kunden. Die so gewonnenen Informationen werden dann auf das individuelle Profil einzelner Kunden angewandt. Dies dient entweder zum Anbieten von mehr oder weniger „maßgeschneiderter Werbung“ (Spam), aber auch zum Selektieren von geeigneten und weniger geeigneten Kunden. Beim Abschluss einer Versicherung versuchen Unternehmen mittlerweile gezielt Kunden mit geringem Risiko durch bessere Konditionen an sich zu binden. Kunden aus Risikogruppen erhalten schlechtere Konditionen oder werden ausgeschlossen.
Ein besonderes Interesse am Zugriff zu persönlichen Daten haben Strafverfolgungsbehörden bei der Bekämpfung von Terrorismus und organisierter Kriminalität. So beschäftigt das Federal Bureau of Investigation (FBI) und die National Security Agency (NSA) Spezialisten zum systematischen Auswerten des Datenverkehrs im Internet. Hier wird eine spezielle Software (Carnivore) eingesetzt, um E-Mails nach bestimmten Stichworten zu durchsuchen. Durch den Einsatz der so genannten „starken Kryptographie“, wie sie das Tool PGP Privatpersonen zur Verfügung stellt, ist jedoch der Wert dieser Software in Frage gestellt. Derartig verschlüsselte E-Mails sind auch von den Experten der NSA nicht mehr zu entschlüsseln. Aus diesem Grunde gibt es Bestrebungen, derartige Verschlüsselungsverfahren zu verbieten. Ein Verbot wäre jedoch kaum wirksam, da eine geschickt verschlüsselte Botschaft mittels Steganographie nicht als solche zu erkennen ist. Das heißt, dass ein solches Verbot den Einsatz starker Kryptographie durch Kriminelle nicht verhindern kann. Betroffen von einem solchen Verbot wären also lediglich rechtschaffene Bürger, die sich selbst gegen kriminelles Ausspähen schützen wollen.
Siehe auch
- Portal Informatik als Wegweiser zu Artikeln rund um die Informatik.
- Liste von Pionieren der Informatik
- Gesellschaft für Informatik, Österreichische Computer Gesellschaft
- Portal Datenschutz zur Einschränkung von Rechten durch Informatik-Einsatz.
- Kybernetik
Literatur
- Heinz-Peter Gumm, Manfred Sommer: Einführung in die Informatik. 9. Auflage. Oldenbourg, München 2010, ISBN 978-3-486-59711-0.
- Hans Dieter Hellige (Hrsg.): Geschichten der Informatik. Visionen, Paradigmen, Leitmotive. Berlin, Springer 2004, ISBN 3-540-00217-0.
- Peter Rechenberg, Gustav Pomberger (Hrsg.): Informatik-Handbuch. 3. Auflage. Hanser 2002, ISBN 3-446-21842-4.
- Uwe Schneider, Dieter Werner (Hrsg.): Taschenbuch der Informatik. 6. Auflage. Fachbuchverlag, Leipzig 2007, ISBN 978-3-446-40754-1.
- Gesellschaft für Informatik: Was ist Informatik? Positionspapier der Gesellschaft für Informatik. Bonn 2005. (PDF, ca. 600 KB), oder Kurzfassung (PDF-Datei; rund 85 kB).
- Vladimiro Sassone: Foundations of Software Science and Computation Structures. Springer, Berlin 2005, ISBN 3-540-25388-2.
- Les Goldschlager, Andrew Lister: Informatik – Eine moderne Einführung. Carl Hanser, Wien 1986, ISBN 3-446-14549-4.
- Jan Leeuwen: Theoretical Computer Science. Springer, Berlin 2000, ISBN 3-540-67823-9.
Einzelnachweise
- ↑ a b Duden Informatik Ein Sachlexikon für Studium und Praxis, ISBN 3-411-05232-5
- ↑ Plug & Pray, Dokumentarfilm mit Joseph Weizenbaum über die Verantwortung des Wissenschaftlers
Weblinks
 Wikibooks: Informatik – Lern- und Lehrmaterialien
Wikibooks: Informatik – Lern- und Lehrmaterialien Wiktionary: Informatik – Bedeutungserklärungen, Wortherkunft, Synonyme, Übersetzungen
Wiktionary: Informatik – Bedeutungserklärungen, Wortherkunft, Synonyme, Übersetzungen Wikiversity: Informatik – Kursmaterialien, Forschungsprojekte und wissenschaftlicher Austausch
Wikiversity: Informatik – Kursmaterialien, Forschungsprojekte und wissenschaftlicher Austausch- Links zum Thema Informatik-Fachbereiche an Hochschulen im Open Directory Project
- Informatik für Lehrerinnen und Lehrer im ZUM-Wiki
- Die Geschichte der Rechenautomaten von der Antike bis in die heutige Zeit
- Informatik Schweiz I-S








Wikimedia Foundation.